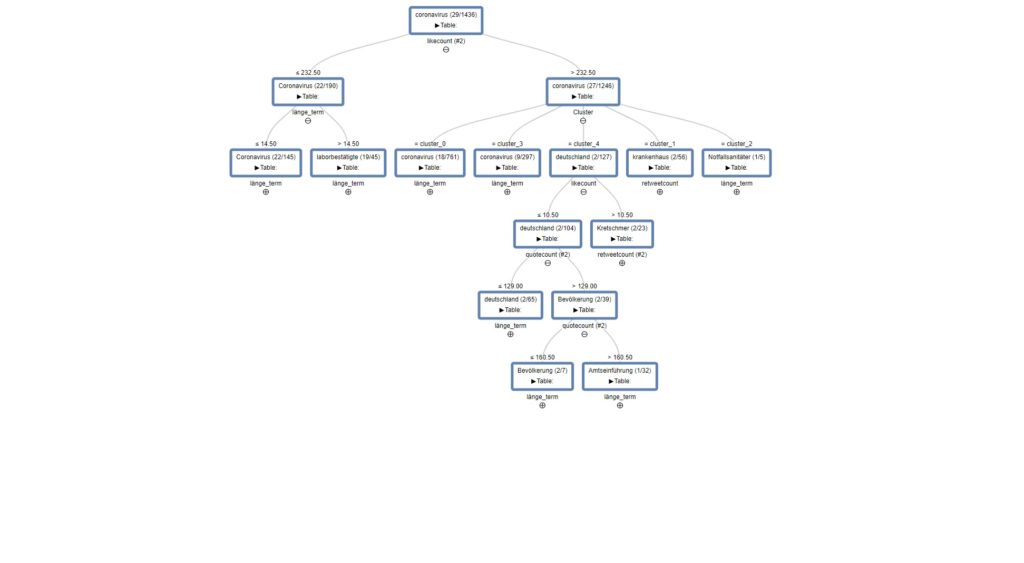
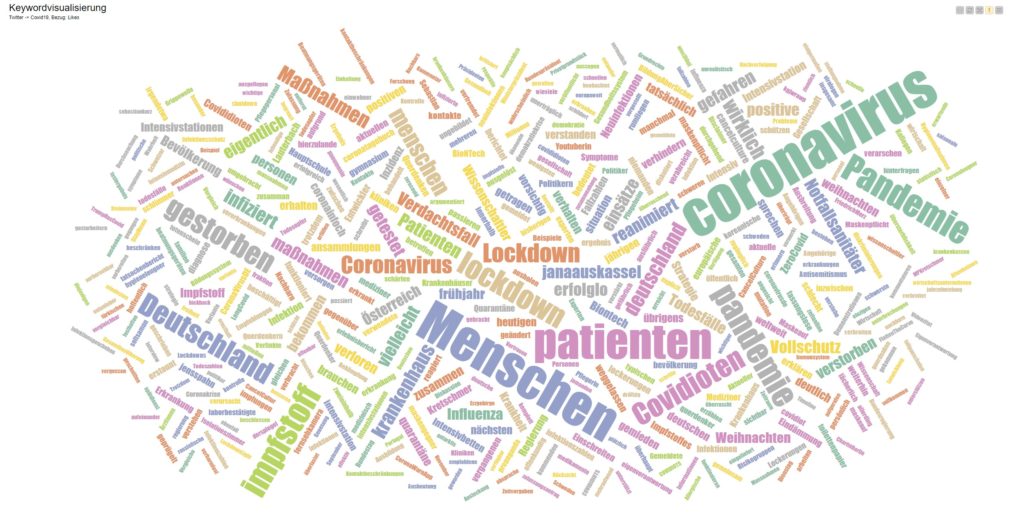
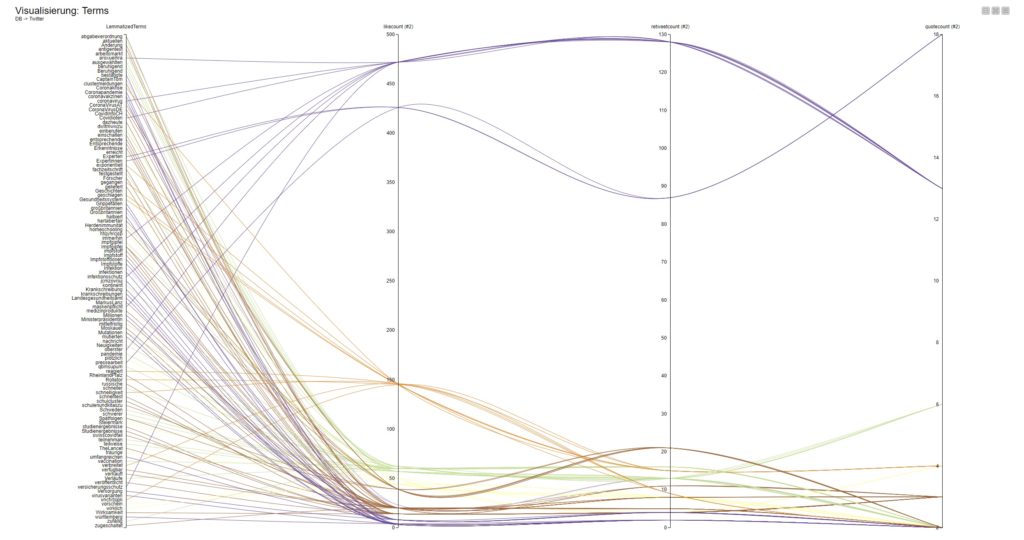
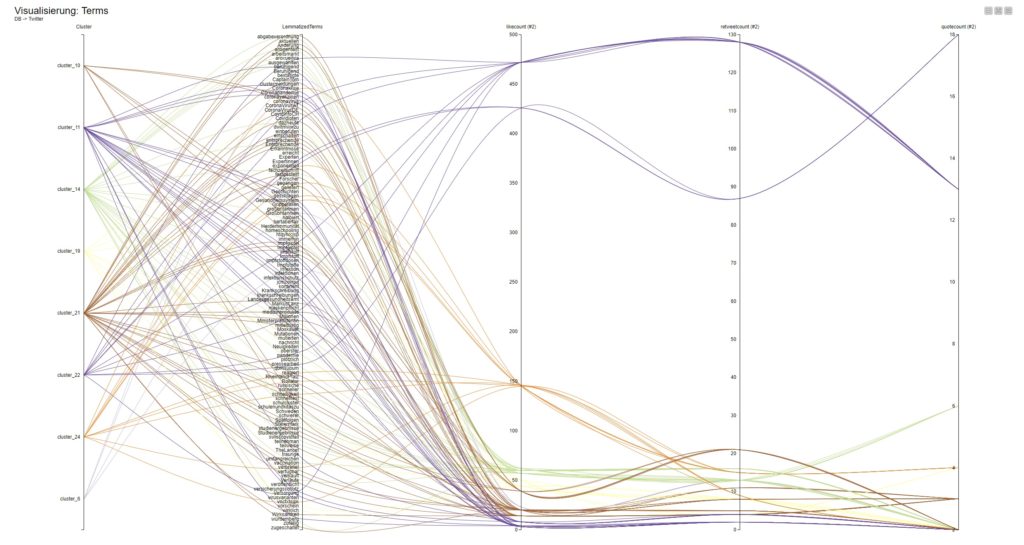
Schnell eine Spalte von Nicht-String auf String umstellen:
- Reinziehen u. Andocken von „String Manipulation.
- Da reinschreiben: „join(string($$$[DeineSpalte]$$$))“
In einer Spalte einen Substring finden und den Fundort innerhalb des Strings speichern:
- Reinziehen u. Andocken von „String Manipulation“
- Da reinschreiben: „indexOf($[DeineSpalte]$, „[DeinSuchbegriff]“)“
- Bei „Append Column“ ggf. eine neue Spalte benennen.
Simple If-Then-Else-Anweisungen durchführen lassen
- Rule Engine in die Arbeitsfläche ziehen und Andocken
- Bei Expression reinschreiben: „$[DeineSpalte$ > 0 =>1 // NOT ($[DeineSpalte]$ >0) => 0“. Das // sagt aus, dass hier ein Zeilenumbruch reingehört.