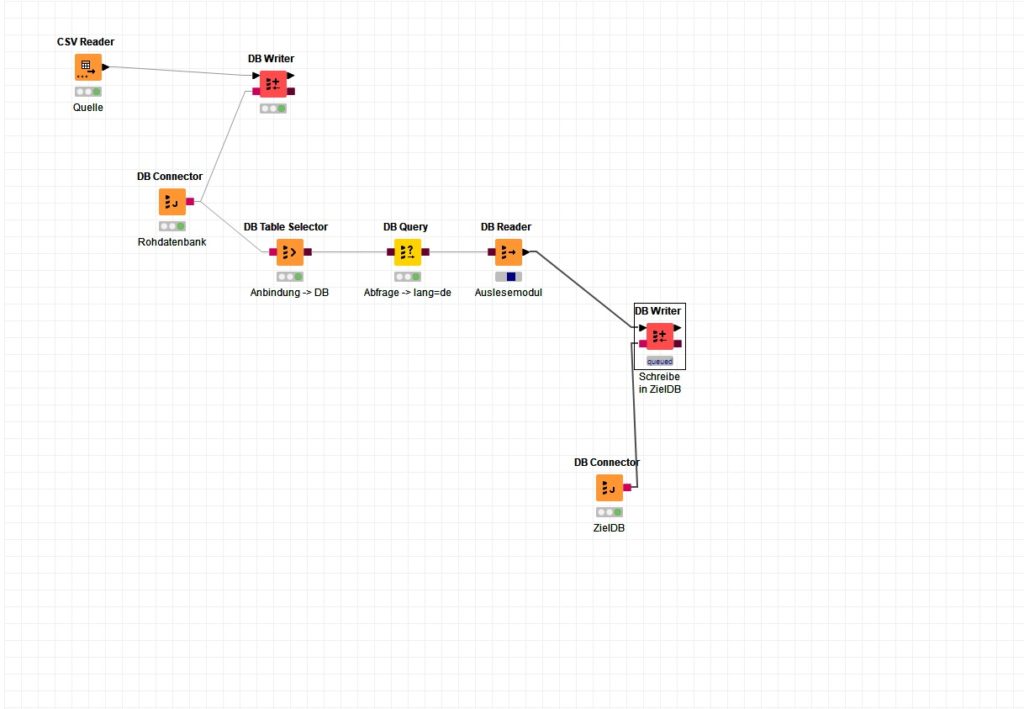
Das ist unser Workflow für den Import und die weitere Verarbeitung des Twitter-Datenpools.
Ich entschied mich hier bewusst für einen Wechsel auf KNIME, weil die Datenbankerstellung (SQLite) per default so realisiert wird, dass eine Spaltengenerierung in Abhängigkeit zum Rohformat (hier: CSV, basierend auf dem Python-Scraper) organisiert ist.
Das Workflow lässt sich problemlos auf verschiedene Szenarien, also „lang=de“ PLUS „content like %xyz%“ erweitern.