So sieht der Twitter-Workflow aus. Man möge sich allerdings nicht täuschen lassen, weil sich hinter den Kästchen hochkomplexe Berechnungsfunktionen zu den Terms, den Themenwelten und Visualisierungen befinden. :-)
Tag-Archiv: datenvisualisierung
Datenvisualisierung: diverse und ergänzende Charts
Diese Module wurden durch das Projektgeschäft explizit angefordert / eingefordert und sie dienen in vielen Fällen zur Untermauerung der Reports, der Strategieempfehlungen oder der Illustration diverser Briefings.
Die Galerie zeigt die Ergebnisse der Analyse von 250.000 Tweets rund um die Themenwelten der Covid19/Pandemie-Problematik.
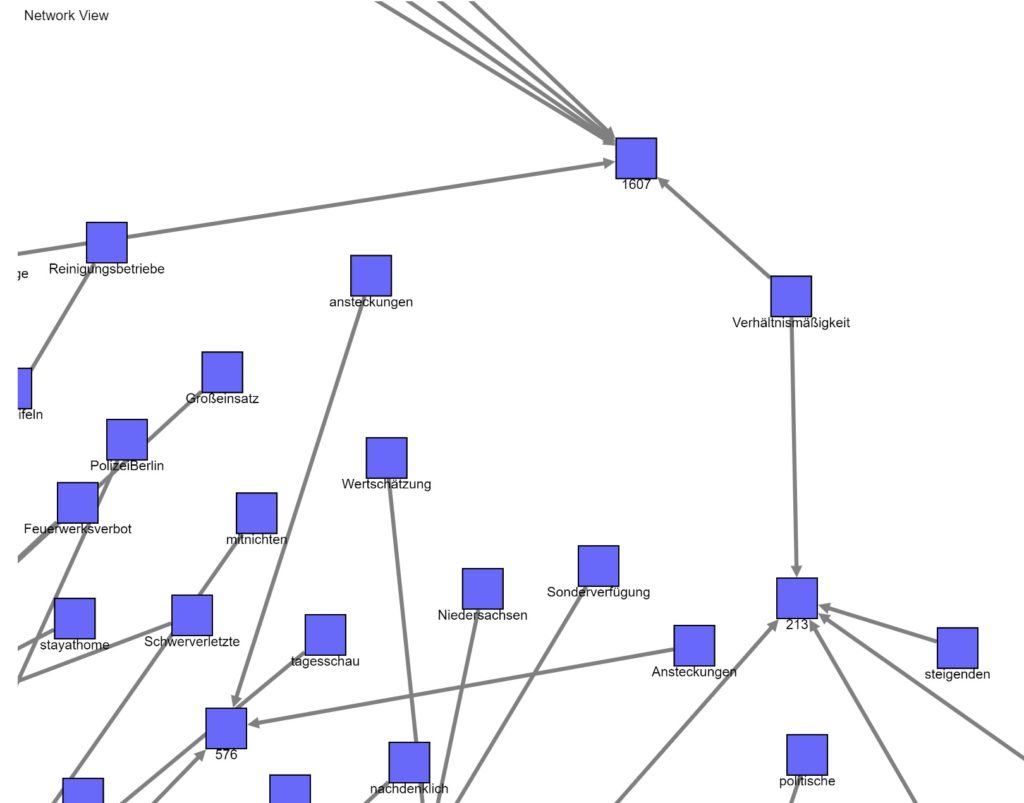
Datenvisualisierung: Modul „Netzwerk Betrachter“
Im arbeitsfähigen Workflow habe ich bewusst das Modul „Network Viewer“ in den 2 bekannten Versionen integriert. Es ist in dem Umfeld sehr komplex und in der Lage, Wort/Themenzusammenhänge verstehbar darzustellen.
Besser: die Screenshots zeigen die Verbindungen zwischen den Themen/Keywords auf Basis der Vorgewichtungen (also: Interaktionsmetriken, Cluster und die allgemeine inhaltliche Nähe zueinander).
Ein Hinweis zu der „Nähe“: ich entwickelte in den letzten Wochen eine abbildbare Logik, welche die Nähe auf Basis externer „Trigger“ identifiziert. Wenn also eine relevant hohe Menge an Personen quasi eine Nähe zwischen den Themen via Kommunikation definiert, sind die Themen miteinander verbunden.
Das sichert die Objektivität der Interpretationsgrundlagen ab.


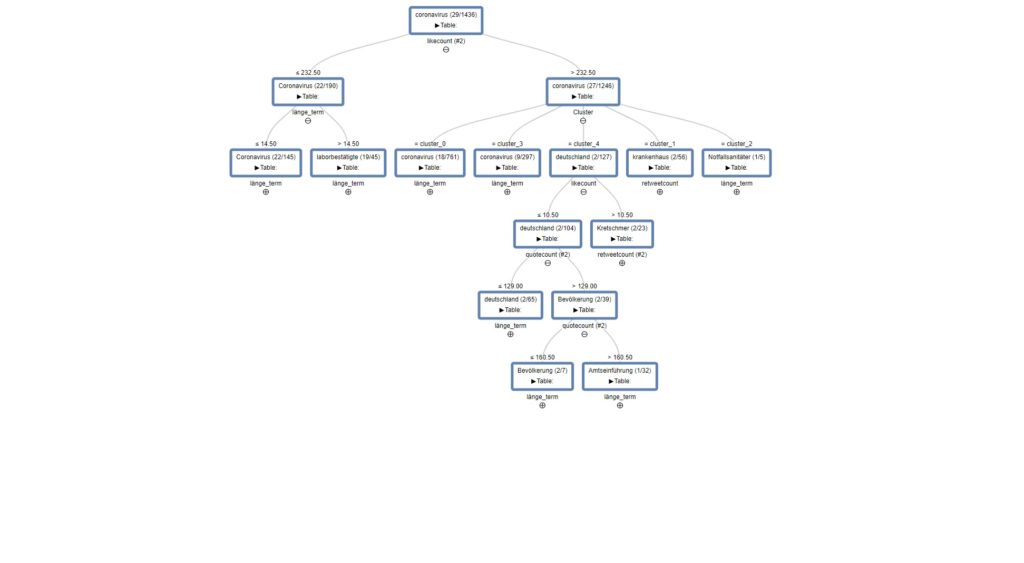
Datenvisualisierung: Modul „Entscheidungsbaum“
Das Modul ist Bestandteil des Twitter-Instagram-Auswertungsworkflow und es verlangt, im Vergleich zu den anderen Features, sehr SEHR viel Arbeitsspeicher und CPU-Ressourcen.
Die beigefügten Bilder zeigen die Ergebnisse der Analyse aus der Twitter/Covid19-Datenmenge (250.000Tweets, lang=DE) und liefert bei entsprechender Interpretationsfähigkeit weitergehende Informationen zu den Filterblasen der beteiligten Accounts.
Wie funktioniert das? Der Baum erlaubt eine Sichtung anhand der Interaktionsmetriken (Likes, Retweets etc.) und listet Wortgemeinsamkeiten zwischen den Ästen auf. Eventuelle Ableitungen erklären wir gern nach Anfrage und für HonorarXYZ.

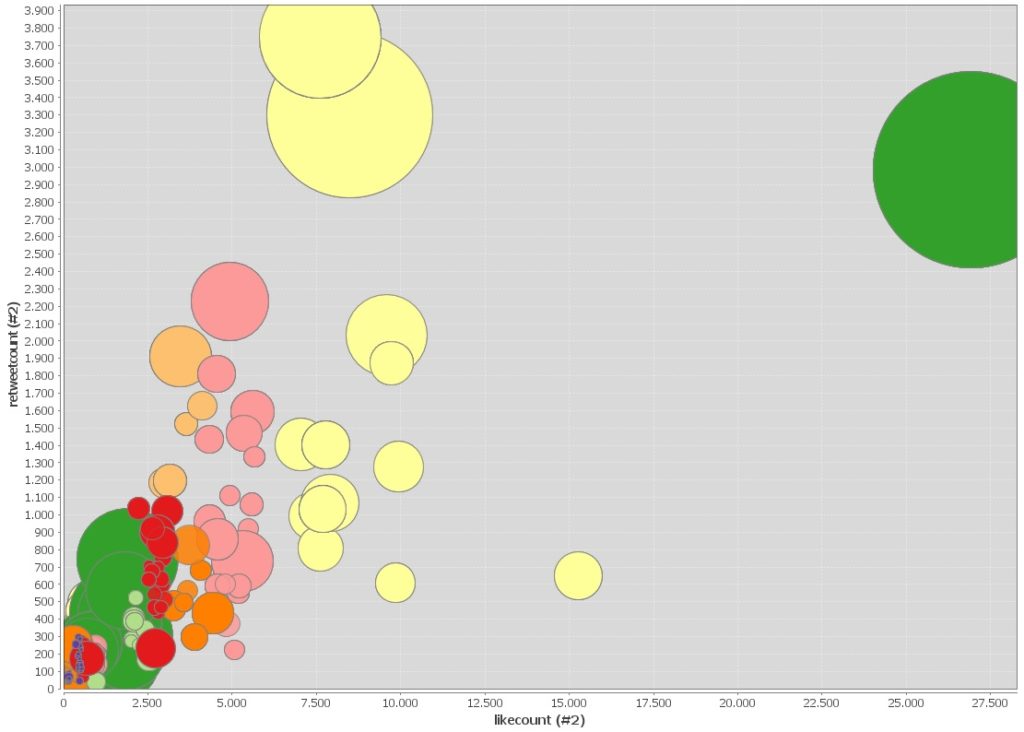
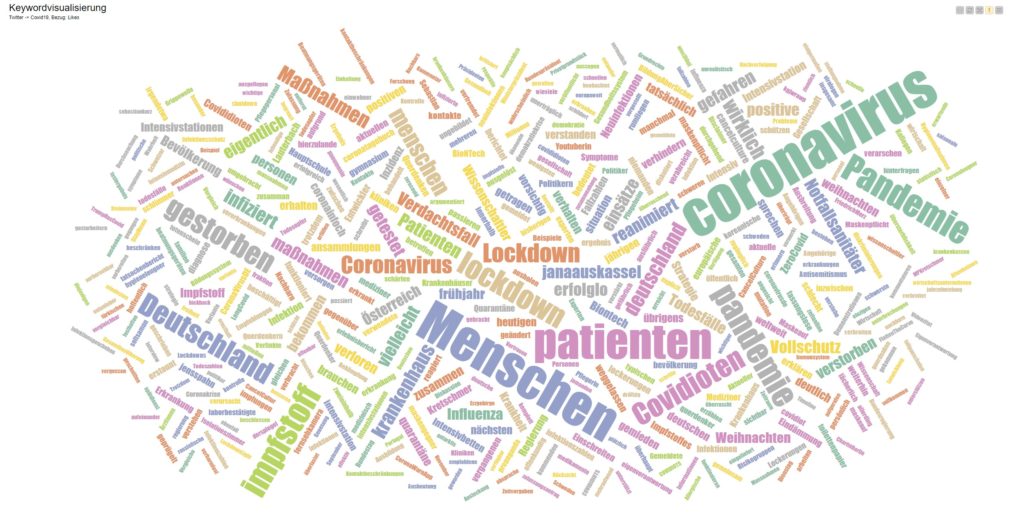
Datenvisualisierung: Modul „Tagcloud“
Das verwendete Modul zeigt hier am Beispiel der Covid19-Datensätze (Twitter, 250.000 Einträge) eine weitere Visualisierungsoption auf Basis einer Vorfilterung.
Bild Nr.01 bezieht sich auf die Anzahl der Likes und Bild Nr.02 hat als Grundlage die Anzahl der Retweets. Die gemeinsame Basis sind vorgefilterte und geclusterte Datensätze (Ausfilterung von SPAM, Fakes, Werbende und Bots).

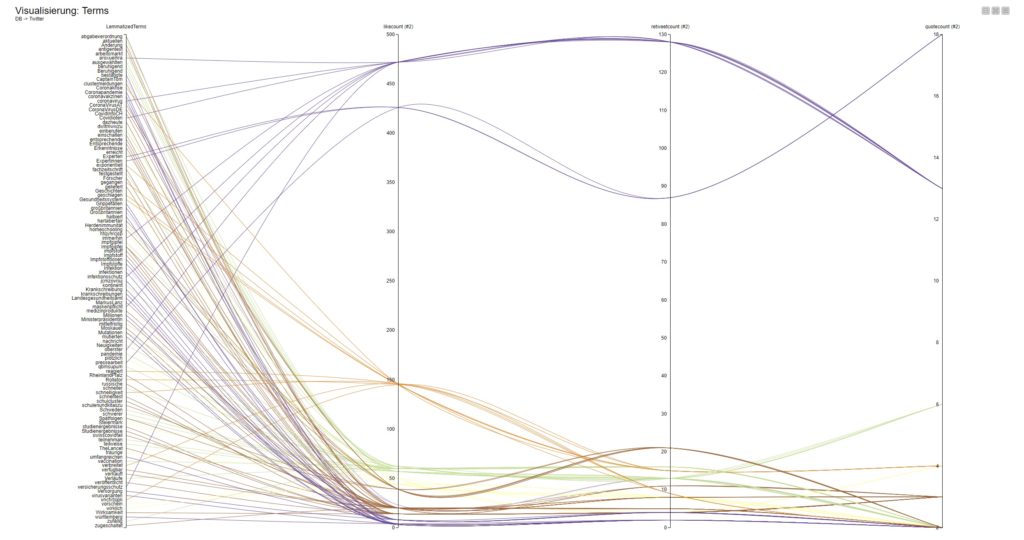
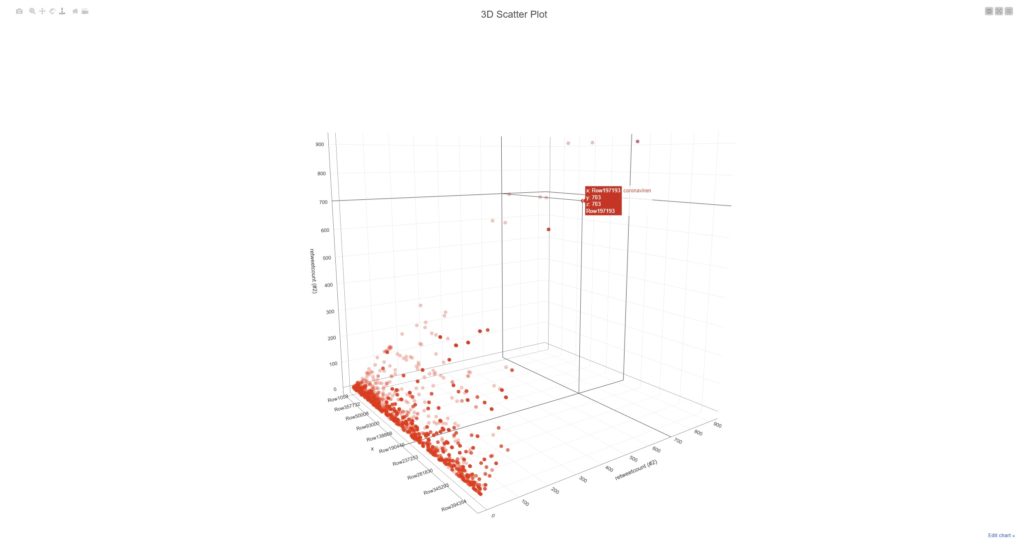
Datenvisualisierung: Modul „Parallel Coordinates Plot“
Das Beispiel verdeutlicht eine weitere Visualisierungsoption, ausgehend von der Themenwelt „Covid19/Coronavirus/Pandemie“ aus der Datenquelle: Twitter.
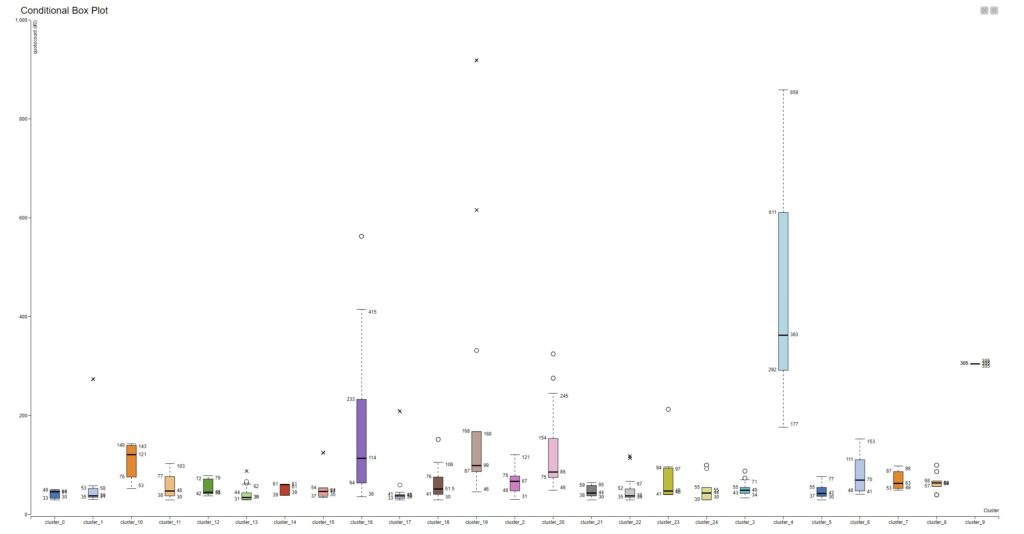
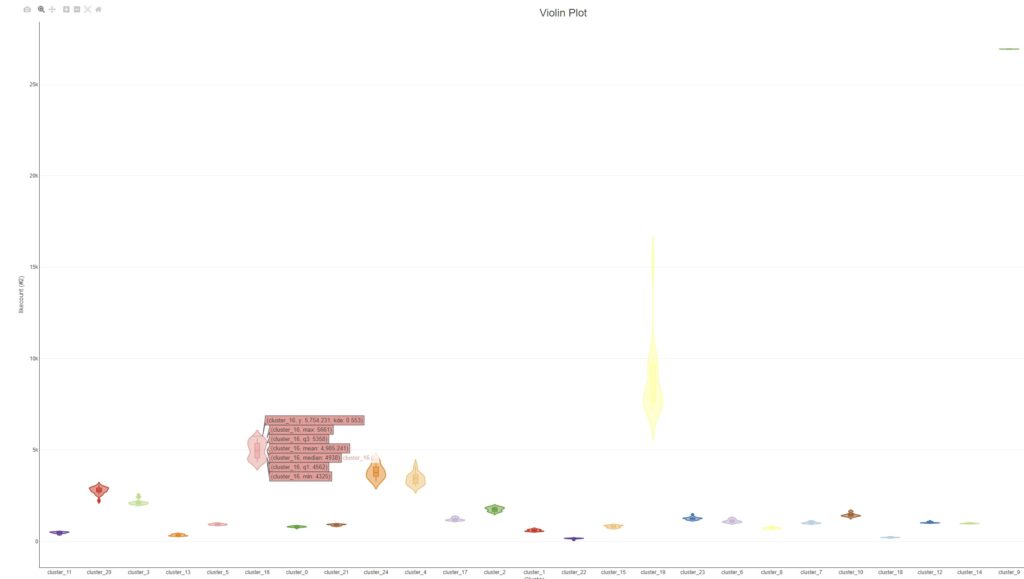
Zur Erklärung: analysiert wurden 250.000 Tweets und wegen der extrem hohen Masse musste hier via KNIME eine Filterung und Gewichtung realisiert werden. Das geschieht im Workflow über die Verbindung mit den bspw. Interaktionsmetriken, der Prüfung auf Inhaltsqualitäten und der Clusterung der Einzeldatensätze mit Hilfe von „k-Means“.
„k-Means“ bietet sich an, weil das Modul letztendlich nur mit den gewünschten Informationen, wie Likes + Retweets + Anzahl-User usw., befüllt werden muss und dann eigenständig die Berechnungen durchführt und die Ergebnisse auf die Einzelterms / Keywords zurückführt.
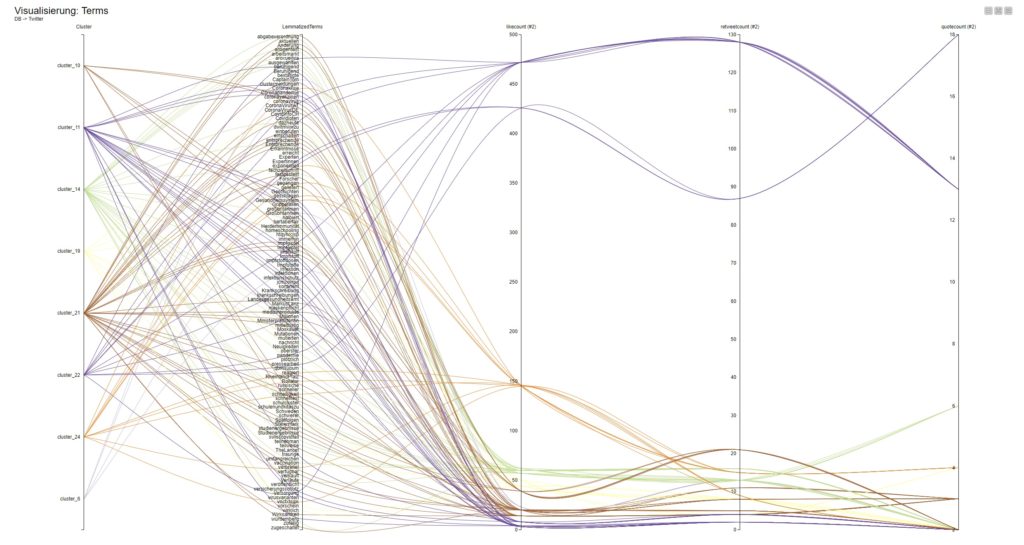
Datenvisualisierung und Start der KNIME-Reihe
Im letzten Jahr fand ich endlich Gelegenheit zur Sichtung diverser Datenmanagement- und Datenauswertungsansätze, weil ich ab einem gewissen Punkt mit meiner Programmierkunst via Delphi viele Szenarien nicht abdecken kann.
So landete ich bei KNIME und fand einen guten Weg, die Workflows zu verstehen und in das Tagesgeschäft einbauen zu können. Interessant ist, dass dieses mächtige und sehr umfangreiche System gefühlt problemlos bspw. die 85GB umfassende Twitterdatenbank oder die 46GB starke InstagramDE/CH/AT-Datenbank andocken, bearbeiten und für diverse Dataminingszenarien ansprechen kann.
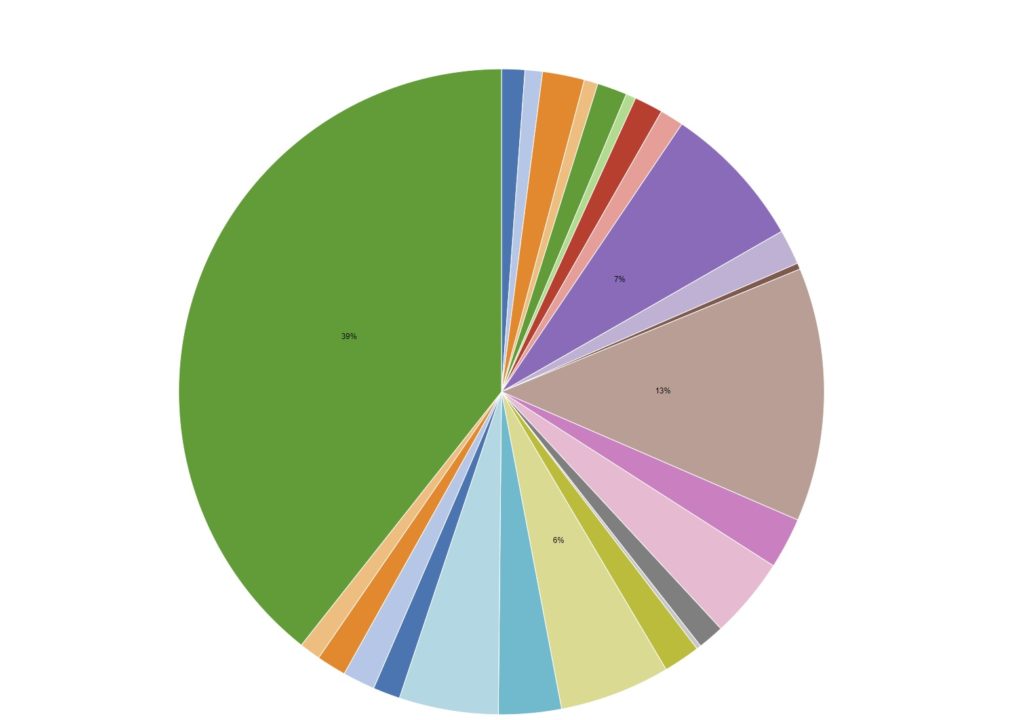
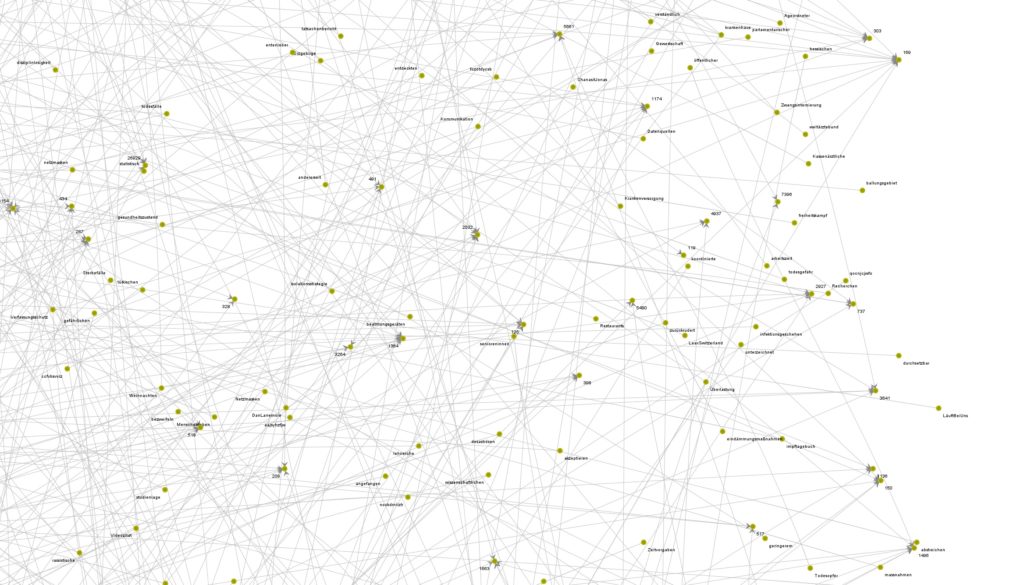
Galerie zeigt 2 Screenshots, welche Terms / Keywords aus den Meinungsbekundungen von ~3.8Mio DE-schreibenden Accounts (Twitter) mit Filter auf Covid19/Pandemie/Coronavirus (Themencluster).
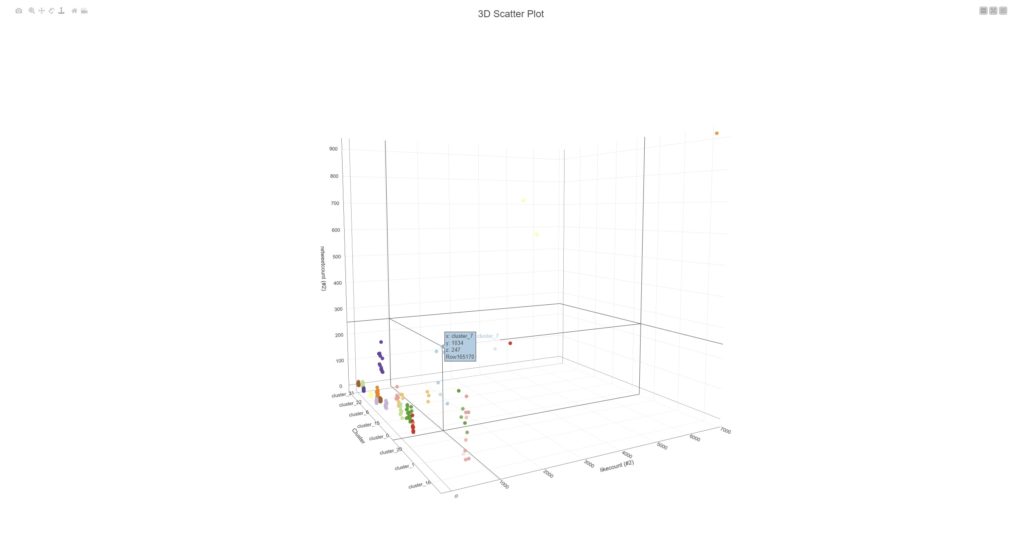
Der „Trick“ ist eigentlich recht simpel: sofern die Datenerfassungsprozedur stabil funktioniert und die Datenbank ordentliche Standards (Technik, Struktur etc.) zeigt, wird via KNIME-Workflow eine Analysemechanik auf die Tweets quasi „angesetzt“. Diese zerlegt den Content in Einzelworte, gewichtet diesen mittels einer Prozedur, welche folgende Metriken beinhaltet:
- Interaktionen
- Zeitstempel
- Anzahl: aktiver Accounts mit Themenfilter
Über diesen Gewichtungsschritt sind Themenzusammenhänge der UnterCluster visualisierbar und das erste Bild der Galerie demonstriert die Zusammenfassung der Themenwolken in Filterblasenstrukturen.
