- Auflistung aller Umgebungen: conda env list
- Eine Umgebung löschen: conda env remove –name testumgebung
- Eine Umgebung installieren: conda create –name testumgebung python=3.5
- Eine Umgebung aktivieren: conda activate testumgebung
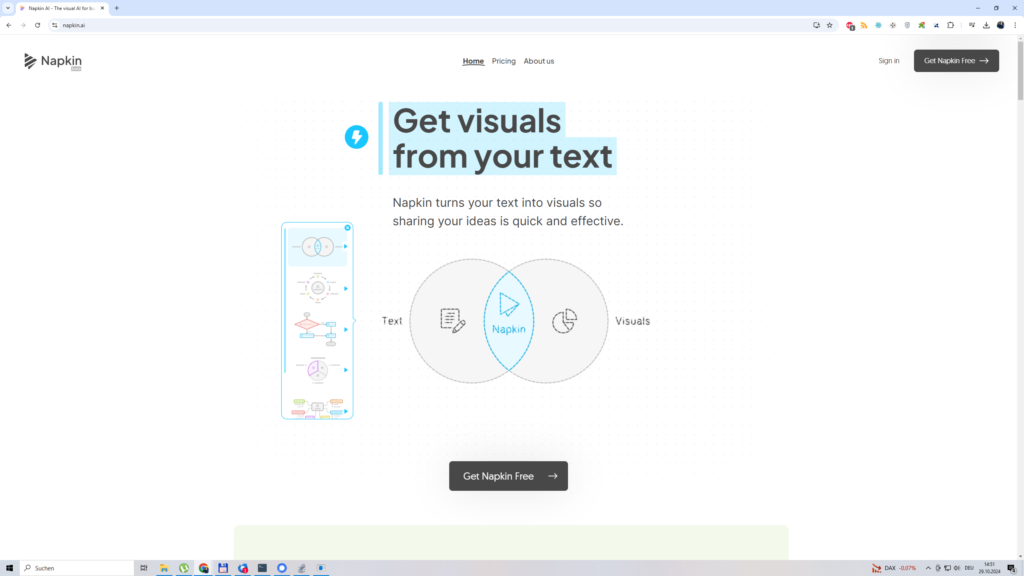
Wie kann ich extrem schnell schöne Grafiken auf Basis eines Textes mit KI erstellen?
Ein hochgeschätzter Kunde / Kontakt kippte bei mir erst heute einen interessanten Fall ein. Der sieht so aus: „Lieber Johannes, ich habe hier einen Text mit technischen Inhalten und da brauche ich unbedingt / ganz schnell schöne Grafiken!“ + „Bitte besorge mir eine Lösung!“
Die Lösung ist simpel und die nennt sich „napkin.ai„. Hier besorgt man sich einen Account (via Google bspw.) und man wird direkt auf eine Fläche, die einen an WordPress erinnert, umgeleitet.
KI – Videoerstellung // PixVerse
„he heats a steak and he is happy“
„a city under siege“
„a walk“
Der Generator produziert im Grunde sehr gute Resultate, jedoch ist er für die aktuell laufenden Experimente eher unbrauchbar. Ich begründe das mit der Unnatürlichkeit der Ergebnisse.
Kling-AI, der letzte Generator aus der Testreihe
Diese Plattform entdeckte ich eher zufällig in den Untiefen von X (Twitter). Beim Testen bespiele ich solche Systeme immer mit zufällig ausgewählten Motiven aus meinem Bestand (i.d.R. Analogscans).
Fazit zu diesem Generator. Im Vergleich zu den anderen Produkten, ist das System ziemlich schlecht. Ich sehe diverse Bugs und gerade die Darstellung von Händen muss zwingend notwendig sauber erfolgen. Sicherlich werde ich das System für kreativere Anwendungen verwenden, oder in die Beobachtung legen. Allerdings eher nicht im Livebetrieb für Marketingzwecke.
LumaLabs – ein Generalist für die Videogenerierung
Der erste Generator, der mir aufgefallen ist, ist LumaLabs. Im Grunde ist hier die Qualität wieder vom Ausgangsmaterial und / oder der Qualität der Arbeitsanweisung (Prompt) abhängig. Die Generierung der Videos kann extrem lang dauern und ich empfehle eine Einbindung und Verwendung, wenn eine Unterfütterung von SocialMedia-Accounts geht. Die Videos lassen sich verlängern und teilweise ist die „Storyline“ durchaus sehr gut.
Hier ein paar Beispiele:
Es sind die üblichen „Bugs“, wie Augen, erkennbar und die Grundlage für die 3 Proben sind hier Analog-Scans (Basis: Lith-Abzüge auf Orwo) und generierte Bilder (Stable Diffusion + Analoglora)
Experimente mit Vertonungen – Gesichtsanimationen
Ein interessantes Werkzeug für diesen „Case“ ist Hedra und diese Plattform ist in der Basis-Variante kostenfrei, erlaubt bis zu 30 Sekunden Vertonung. Es stehen einige Standardstimmen zur Auswahl (in dem Beispiel ist es die Charlotte) und es lässt sich auch etwas Eigenes via Mikro da einspielen. Die Qualität des Videos (Hinweise: Augen, Bewegungen, Mimik und Gestik) ist von Ausgangsmaterial abhängig. Je besser die Kontraste und die Auflösung ist, desto besser ist eben auch das Endresultat.
Bei dem Beispiel wählte ich eine virtuelle Person – generiert via StableDiffusion unter Einbindung eines unserer AnalogLoras.
Frische SEO/Onlinemarketing-Referenz
Ausgangslage: verbrannte Domain -> kein klass. Blackhat, sondern Contentproblematik, Inhalt: ~80k Artikel rund um Wohnen, Deko etc.
Grobskizzierung der Strategie:
(Onpage)
(1) Contentproduktion mit Quelle GPT4All + Exotendatenmodell
(2) Manuelles Feintuning der Inhalte aus (1)
(3) Keywords / Themenrecherche ausschließlich über Instagram -> Fokus auf Comments
(Offpage)
(1) Bildproduktion via StableDiffusion unter Einbindung eigener Loras (Loratraining mit meinem Analogfotomaterial)
(2) Befüllen v. Pinterestaccounts, je Kategorie / Galerie mit max. 25% Verlinkung auf Seite
(3) Shares + Likes innerhalb der Pinterestaccounts
(4) Galeriegestaltung / Benennung nach Scrapen der „Suchvorschläge“, ausgelesen aus Pinterest
(5) Verlinkung der Accounturls in rotierende Blogrolls auf eigene „privat aussehende“ Blogs
(6) Punktuelles Weiterleiten v. Fotos aus Pinterestaccounts auf kleinere Twitter-Accounts, die NICHT in DE / DACH lokalisiert sind.
(7) Push auf Seite via eigene hochgezüchtete Instagram-Accounts (Bio u. teilw. Postings)
Fragen? Kontaktwunsch?


Freigabe: neues Lora für die BildGenerierung (KI)
Die Trainingsdaten basieren auf einige meiner Analogfilme, die ich mit Hilfe der Technik „PeeSoaked“ kunstvoll modifizierte.
URL (Download): https://civitai.com/models/502769/soakedpee
Wechsel von Plesk zu Webmin/Virtualmin
Unser „Provider“, der die „1“ im Namen trägt dachte sich vor einiger Zeit, dass es irgendwie cool wäre, an den Betriebssystemen zu basteln und uns nicht darüber zu informieren, dass die bezahlte Plesk-Lizenz nicht mehr funktioniert.
Ich fand das eher unwitzig …
Hier der Lösungsweg für den Wechsel von Plesk zu Webmin/Virtualmin
Putty besorgen und da entsprechend den Angaben einloggen (IP, root, passwort etc.)
- install + update ubuntu
sudo apt update
sudo apt install ubuntu-release-upgrader-core
sudo do-release-upgrade
sudo apt install certbot
sudo apt install mysql-server - sudo apt update
sudo apt install curl - curl -o setup-repos.sh https://raw.githubusercontent.com/webmin/webmin/master/setup-repos.sh
sh setup-repos.sh - apt-get install –install-recommends webmin
- sudo sh -c „$(curl -fsSL https://software.virtualmin.com/gpl/scripts/virtualmin-install.sh)“
- https://xxx.xxx.x.xx:10000/ root + passwort
- Virtualmin -> Adresses and Networkung -> Change IP-Adresses -> xxx.xxx.x.xx
- Alle Domains installieren -> Virtualmin -> Manage Virtual Server – Setup SSL Certificate -> Lets Encrypt
Alles Relevante veranlassen und bei Putty sudo systemctl restart apache2
Neue Dienstleistung: „Bildgenerierung“ und KI-Training.
Ab sofort bieten wir folgende Dienstleistung an:
- Analyse + Beratung zu den ansprechbaren Zielgruppen
- Entwicklung von Prompts unter Berücksichtigung der Datenmodelle (Stable Diffusion)
- Training von sog. „Concept“-Loras
- Training von sog. „Objekt“-Loras
- Aufsetzen der BildgenerierungsKI-Umgebung
- Generierung von ~100 Bildern je Prompt / Szenarium unter Berücksichtigung der üblichen Auflösungen
Folgende Anwendungen ergeben sich aus diesem Komplex:
- absolut perfektes Briefing für Fotograf:innen, da den Einkäufer:innen kreativer Dienstleistungen (Fotografie, Bildgestaltung etc.) auf Basis der Bilder die Grundlage für Briefings gegeben werden können.
- Stimmungsbilder für Blogs und Socialmedia-Auftritte
- …
Interesse? Gerne Kontakt.


