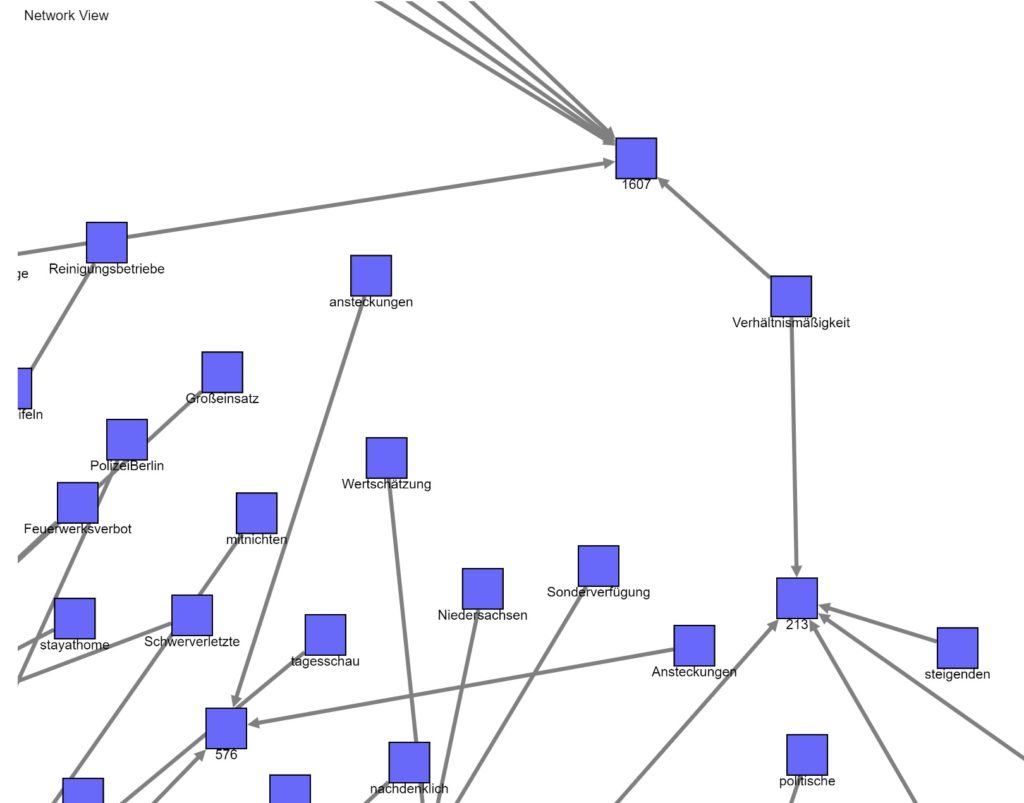
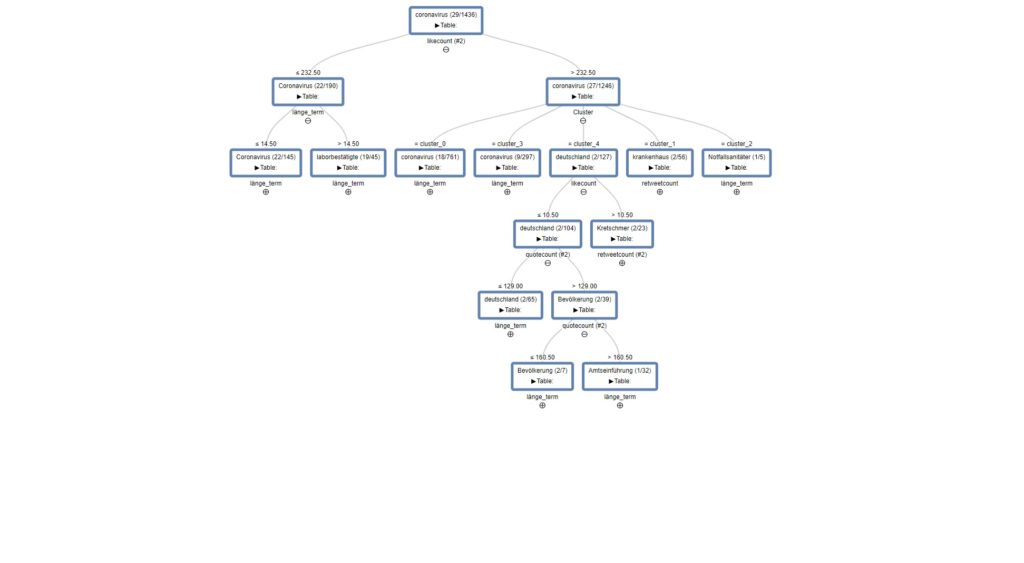
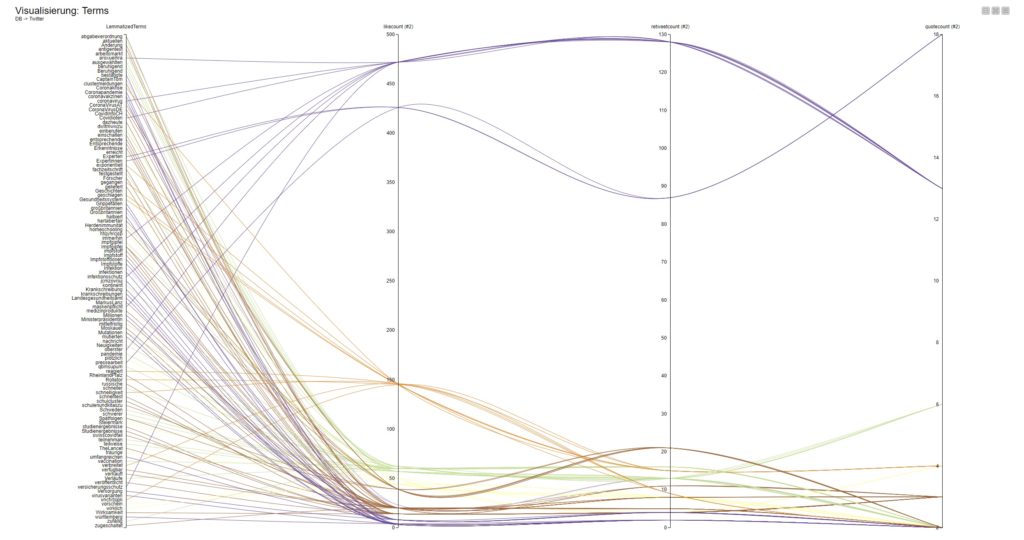
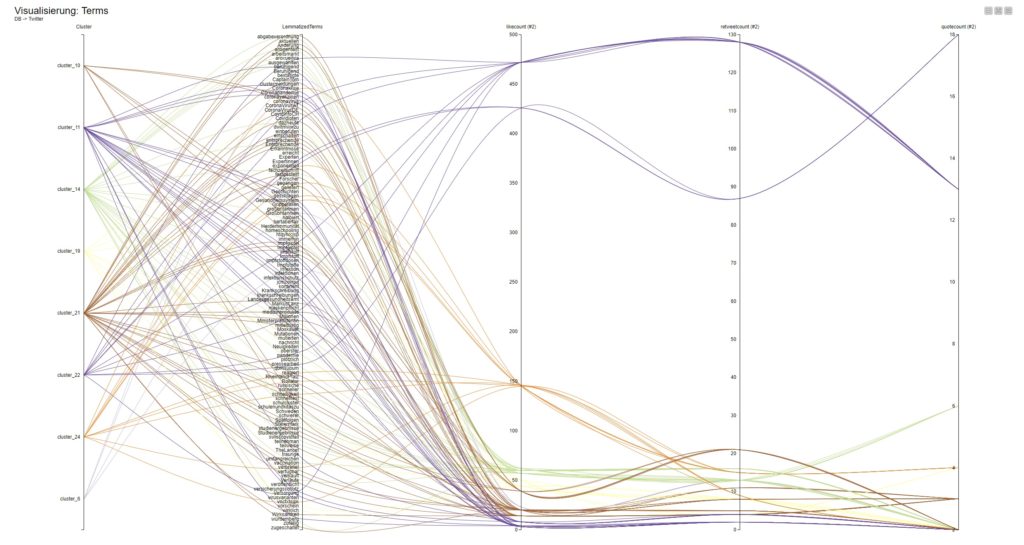
Im arbeitsfähigen Workflow habe ich bewusst das Modul „Network Viewer“ in den 2 bekannten Versionen integriert. Es ist in dem Umfeld sehr komplex und in der Lage, Wort/Themenzusammenhänge verstehbar darzustellen.
Besser: die Screenshots zeigen die Verbindungen zwischen den Themen/Keywords auf Basis der Vorgewichtungen (also: Interaktionsmetriken, Cluster und die allgemeine inhaltliche Nähe zueinander).
Ein Hinweis zu der „Nähe“: ich entwickelte in den letzten Wochen eine abbildbare Logik, welche die Nähe auf Basis externer „Trigger“ identifiziert. Wenn also eine relevant hohe Menge an Personen quasi eine Nähe zwischen den Themen via Kommunikation definiert, sind die Themen miteinander verbunden.
Das sichert die Objektivität der Interpretationsgrundlagen ab.