Nach einigen Gesprächen und diversen Diskussionen entschied ich mich zur Freigabe eines spezielleren Accounts zwecks Analyse der Fragen:
– Wie funktioniert das Ding mit Twitter eigentlich?
– Wie lassen sich bei Twitter mit welchem Aufwand (!) Autoritäten etablieren?
– Wie funktioniert bei Twitter die Statistik und die Auswertung der systemeigenen Statistik?
– Wie funktioniert bei Twitter die Verwertung der Hashtags?
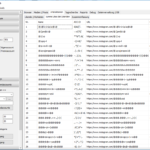
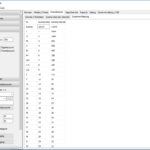
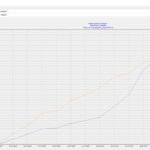
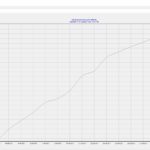
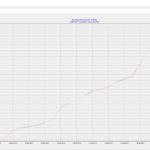
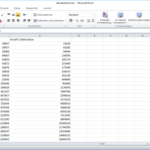
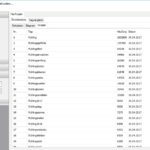
Hier nun der erste Zahlenstand mit (Re)etablierung des Accounts.

Der Account bedient folgende Themen / Inhalte:
– Momentaufnahmen, Schnappschüsse (Digital, div. Rundreisen und sonstige Motive)
– Neu: Analogfotografie und Dokumentation der „Experimente“ mit div. Materialien, Farben und Motive
– Retweets: überwiegend S/W, monochrome
– Grundbefüllung via IFTTT vom Instagramaccount ausgehend
Die aktuellen Zahlen und auch Rückmeldungen via Twitter-Kontakte sind soweit überraschend gut und ich werde zeitnah analysieren, wie sich der Beziehungsaufbau bei dem System effektiver organisieren lassen kann.
Fragen, Austauschanregungen und Kontakt bitte via bekannten Telefonnummern (siehe Impressum)