Gestern bereinigte ich einen Bug in den Systemen von „InstaLOC“. Hierbei ging es um eine Aufbereitung der Locationdatensätze (1.7Mio) in eine leichter lesbare Form. Aufgefallen war mir, dass bspw. chinesische Zeichen in Form von „???“ beim Auslesen und Übertragen dargestellt wurden. Dies ist das Unicode-Problem und meine Lösung war simpel: Wechsel der Spaltenvariable von „VARCHAR“ auf „STRING“.
Kategorie-Archiv: Alle Blogbeiträge
Notiz: Instagramaccount aufräumen und effektiv managen.
Vor einigen Tagen beschloss ich eine Neuausrichtung meines Accounts und stand vor folgenden Problemen:
(1) Wie kann man extrem schnell und mit möglichst wenig Aufwand uralte Beiträge entfernen?
(2) Wie räumt man schnell und effektiv die Aboliste auf?
Ninjagram und ähnliche Systeme wurden gesichtet und getestet. Hier stellte ich einen hohen Zeitaufwand fest und landete bei der Android-App „Cleaner for Instagram„. Das Werkzeug erlaubt das Entfernen von mehreren 1000 Beiträgen per Stapelverarbeitung, filtert Abos nach Aktivitäten (Follow / NON-Follow / Interaktionsfreudigkeiten etc.) und kostet – je nach Funktionsumfang – zwischen 3,09 € bis 4,89 €.
Projekt InstaLOC, Aktuelle Statistiken
Der aktuelle Datenbestand umfasst:
587.903 Locations inkl. Geocodes, IDs und Namen
12.669.502 Unique Tagclouds
5.633.457 Beiträge ohne Locationzuordnung
8.516.617 Beiträge mit Locationzuordnung
4.863.200 codierte User
10.700.170 Unique Zeitstempel (Beiträge)
Die Masterdatenbank umfasst alle erfassten Datensätze und die Scrapingtechnologie schafft das genannte Volumen innerhalb von 3-4 Werktagen.
Datenbanken, Bigdata und die Aufbereitung der Abfragen
Nach Durchsicht der aktuellen Datenbasis aus den Projekten „HashtagDB“ und „InstaLOC“ musste ich etwas nachdenken und mir eine Lösung zur Aufbereitung der extremen Datenfülle überlegen. Das Problem ist, dass zwar via SQLite-Studio und der integrierten SQL-basierten Abfragemöglichkeiten gute Abfrage- und Auswertungsmöglichkeiten vorliegen, jedoch lassen sich keinerlei Gewichtungsprozeduren hier realisieren. Ein angedachter Lösungsweg war die Anbindung von Excel via der bereitgestellten API. Trotz (technischer) Realisierbarkeit tauchten auf verschiedenen Rechnern immer wieder Ressourcenprobleme auf. Ich entschied mich heute (final) für eine 3-Stufenlösung:
(1) Vorgewichtung
Die Vorgewichtung erfolgt via SQLite-Studio in Form der – hier dokumentierten – Abfragen. Wir, oder ein geschulter Externer, setzen entsprechende Metaebenenanfragen an die Datenbanken ab und extrahieren die Ergebnisse im Standard-CSV-Format.
Metaebenenanfragen können sein:
(a) Gib mir alle Tagwolken aus dem Zeifenster 08-2018 aus, die mind. zum Inhalt „urlaub“ haben und in dem Raum Leipzig gepostet wurden.
(b) Zeige mir die beliebtesten Postings aus dem Raum Berlin mit Inhalt „Schmuck“.
(2) Nachgewichtung
Die Nachgewichtung erfolgt hier mit Hilfe einer kleinen Software. Diese importiert die Ergebnisse aus der „Vorgewichtung“ und liefert über geeignete Berechnungsfunktionen Interpretationshinweise zu:
(a) Welche Beziehungen existieren zwischen den Hashtags?
(b) Welche Beziehungen existieren zwischen den Tags, den Locations und den aktiven Accounts?
(c) Wer gewichtet Trends in welchem Zeitfenster, an welcher Location?
(3) Interpretation und Reporting
Die Nachgewichtungssoftware exportiert die generierten Gewichtungsergebnisse in ein geeignetes Standarformat, welches von Openoffice und Excel akzeptiert wird. Die grafische Auswertung und die Aufbereitung für nachgelagerte Beratungsgespräche und Interpretationen im Team / bei den Kund_innen findet genau in diesem Umfeld statt.
Privat vertrete ich den Anspruch an die absolute Transparenz bzgl. der Rohdaten / der Datensätze. Ich habe aber auch, nach verdammt vielen Diskussionen, verstanden, dass 4-20GB große Datensätze von Geschäftsfreund_innen und Kund_innen nicht behandelbar sind. Daher der skizzierte Kompromis der Aufbereitung via Excel, Powerpoint & Co. und Quercheck auf die gefilterten Daten aus der „Nachgewichtung“.
Anfragen, Hinweise oder Nachfragen gerne via Kommentar, eMail oder Telefon.
Influencermarketing, Instagram und das (lästige) Problem der suboptimalen Followerzahlen?
Ich glaube, dass die Leser_innen des Arbeitsblogs mit extrem hoher Wahrscheinlichkeit meine enorme Skepsis gegenüber der „offziellen“ Strategie des Influencermarketings verstanden haben und ich denke, dass ich etwas mehr Erklärung schuldig bin. Es ist eigentlich einfach und bei Sichtung der Kritiken (also … nicht nur meine) tauchen immer wieder Argumente rund um die einkaufbaren Follower auf und hier vertrete ich nun einmal den Ansatz, dass man die Strategie „Influencermarketing“ eben wegen der massiven Kritiken nicht auf Basis der Subjektivitäten „Erfahrung“ oder „Zwischenmenschlichkeit“ beurteilen muss, sondern man MUSS diesen Ansatz eben auch mit Hintergrundwissen zu den Einflussfaktoren / „alternativen“ Strategien jedes Mal neu bewerten (also: je Szenarium, je Projekt, je Kund_in usw.).
Nun ist eine spannende Problemquelle beim Instagrambasierten Influencermarketing eben die Frage, ob die einkaufbare Reichweite (hier: Follower) auch tatsächlich „real“ ist. Ich wundere mich immer wieder, wie selten eben diese unfassbar spannende Problematik so selten und so unbefriedigend diskutiert wird, obwohl gefühlt einige 1000 Anbieter mit entsprechenden Kaufangeboten auf dem Markt völlig problemlos recherchierbar sind. Es gehört für mich zum Tagesgeschäft dazu, die Konkurrenz zu beobachten, welche eben diese spezielle Marketingform anbietet und natürlich entdecke ich da viele Blogbeiträge und Erfahrungsberichte zu wahnsinnig emotional ausgeschmückten Worstcase-Szenarien und ich mache mir da immer einen Spaß und frage nach konkreten Erfahrungen. Sprich: man kann in der hochintellektuellen Sparte „Marketing“ ja schlichtweg nur zu Dingen Formulierungen tätigen, von denen man schlichtweg auch etwas versteht und hierzu gehört auch das Durchspielen von Experimenten und NICHT (!) das kritiklose Wiederholen von nicht nachprüfbaren Experimenten der Werbeszene. Man sollte schon im Interesse der Sichtung dieser einkaufbaren Follower sich um das Erwirtschaften eigener (!) Erfahrungen bemühen.
Eines davon erledigte ich vor geraumer Zeit mit einem extra aufgesetzten Instagramaccount und hier ging ich so vor:
[1] Recherche bei Google
https://www.google.de/search?q=buy+instagram+followers+cheap
(„cheap“ deswegen, weil ich kein Interesse am Verspielen von Geld hatte.)
Im Rahmen des ersten Grobchecks entdeckte ich, dass die vielen Anbieter sich „beweisen“ wollen und man bietet potentiellen Kund_innen eben auch Testpakete – natürlich – kostenfrei an.
[2] Recherche bei Google, nach kostenlosen Followertestpaketen
https://www.google.de/search?q=buy+instagram+followers+free+trial
https://www.google.de/search?q=10+free+instagram+followers+trial
https://www.google.de/search?q=50+free+instagram+followers+trial
https://www.google.de/search?q=20+free+instagram+likes
Ich sehe nun einen bunten und wunderschön ausgeschmückten Laden mit sehr vielen interessanten Angeboten und weil mir hier der moralische Zeigefinger (oder besser: der basislose moralische Zeigefinger) keine Freude bereitet, experimentierte ich mit den folgenden Angeboten ein wenig herum:
[Pro Forma – Hinweis]
Ich übernehme keine Verantwortung, wenn die Benutzung der nachfolgenden Angebote nicht die gewünschten Effekte produziert.
http://www.buzzdayz.com/free-instagram-follower-trial/
https://www.quickfansandlikes.com/
http://www.gramozo.com/free-trial/
https://www.getmassfollowers.co.uk/
http://buyhugefollowers.co.uk/
http://www.thebestfollowers.co.uk/
https://instalegendary.com/
https://soclikes.com/
https://getmoreinsta.com/index.php?page=addfreefollowers
Eine besonders interessanter Anbieter ist:
https://plusmein.com/index.php?page=addfreefollowers
Dieser erlaubt das Einbuchen von jeweils 20 Follower je 24 Stunden und damit kann der Experimentalaccount über einen schönen Zeitraum hinweg „wachsen“. Eine „Runde“ des Testaccounts durch diese Liste „erntete“ zwischen 250 und 300 relativ stabile Follower.
Ein paar Worte zur Bewertung der zusammengeschnorrten Follower.
Ich habe hier eher „gemischte“ Gefühle zur Qualität: ich sehe klischeehafte Fakeaccounts (also: junge Frau, extrem viele Abos, wenig Follows, keine|wenig Medien) und ich sehe natürlich auch sehr natürlich wirkende Accounts und das lässt mich fragen, woher diese Anbieter denn die vermittelbaren Accounts überhaupt nehmen und ein wenig Recherche ergab, dass die meisten Quellen sich auf das Interaktionen – gegen Coin – System beziehen. Interessant ist der Anbieter „plusmein.com“, denn hier entdeckte ich in den ersten Testläufen durchaus auch neue Follower, deren Daten und Medien dem typischen Bild des einkaufbaren Influencers entsprechen.
Ganz ehrlich: ich habe keine Ahnung, wie dieser Anbieter arbeitet und woher die Accounts stammen und im Moment theoretisiere ich in Richtung „Engagement Gruppe“, wobei das natürlich nicht final verifizierbar sein dürfte. Obwohl die Qualitäten wechselhafter Natur sein können, sehe ich auch, dass der Schwundfaktor im – sagen wir mal – „natürlichen“ Rahmen bleibt, wobei ich auch sehe, dass die Interaktionen da, wenn auch äußerst gering sind.
Komme ich nun zur moralischen Einordnung und hier vertrete ich – wie erwähnt – eine eher pragmatische Sichtweise, gerade deswegen, weil die Einordnung der Followerlisten in Fake / Non-Fake sehr schwierig ist. Natürlich existieren sehr viele Indikatoren für eben „schwierige“ Ansätze innerhalb einer Accountstruktur und diese sind Ungleichgewichte in den Zahlen, komische Kommentare, aber mal ganz ehrlich: es gibt durchaus Menschen, die wie die Irren unfassbar vielen anderen Menschen folgen, dann gibt es Accounts, die ohne Verantwortung oder „Zutun“ eben Ziel von Spamcommentattacken werden. Mir passiert sowas ständig, den Kund_innen ebenfalls und ich sehe da immer wieder automatisch generierte Comments aus eben auch der Feder deutscher Accounts aus der Berater_innenszene, der Socialmediaberater_innen und selbstverständlich auch völlig normale Firmen. Das hängt auch damit zusammen, dass viele eben diese Werkzeuge wie „Ninjagram“ verwenden und die Hoffnung hegen, dass abgesetzte Kommentare Aufmerksamkeit erzeugen.
Also: „Fakes“ sind definitiv nicht sauber und extrem eindeutig identifizierbar und das gilt auch für den Kauf oder das oben beschriebene Zusammenschnorren. Also quält mich eine Frage: Wieso existieren stark moralisierende Argumente rund um ein nicht nachprüfbares Thema? Ich erkenne keinerlei Logik in der eigenen Geschäfts- und Dienstleistungsaufwertung, wenn nicht überprüfbare Followerlisten als pauschal „sauber“ deklariert werden und das via Behauptung schlichtweg „nur“ in den Raum gestellt wird.
Ob nun diese Positionierungsvariante edel, gut, moralisch einwandfrei oder sogar „praktikabel“ ist, muss und soll jeder Mensch für sich selbst entscheiden. Mir steht das Erheben des moralischen Zeigefingers nicht zu, würde aber das eventuelle Einsatzszenarium immer wieder neu bewerten und während eines eventuellen Schnorrens / Einkaufens unbedingt auf folgende Dinge achten:
(1) Absolut saubere Contentqualität.
(2) Klare, deutliche und zielgruppengenaue Kommunikation.
(3) Natürliche Marketingmaßnahmen
Fragen, Gedanken, Hinweise? Gern über Kommentar oder via Telefonat. Ich suche übrigens tatsächlich händeringend nach einem sauberen Followerlistenauswertungsalgorithmus.
Influencermarketing, Influenceraccounts und das (lästige) „Problem“ der LIKE-Zahlen
Vor einigen Tagen hatte ich das Vergnügen, Gast auf einer dieser Influencermarketingwerbeveranstaltungen sein zu dürfen. Hier wurden auch mir diverse und spannende Strategien zur Positionierung von Produkten, Dienstleistungen und auch virtuellen Existenzen in den Socialmedia vorgestellt. Ich rechnete selbstverständlich auch mit einer eindeutigen Ausrichtung auf eben das (!) Trendthema INFLUENCERMARKETING.
Soviel dazu: der Vortrag (oder besser: die Akquiseveranstaltung) lieferte viele Argumente in Richtung der simplen Skalierbarkeit von eben der Zusammenarbeit mit Influencern und da tauchten unfassbar viele Fragen in meinem Hirn auf, welche ich auch selbstverständlich vor Ort ausformulierte.
Beispiele sind:
(a) Wer garantiert mir, dass die Reichweitenzahlen und die erreichbaren Zielgruppen überhaupt „natürlich“ / „natürlich gewachsen“ sind?
(b) Welche Verifikationsmöglichkeiten existieren denn in der Begutachtung dieser absolut wichtigen Zahlen?
(c) Wie lassen sich Prognosen zur wirtschaftlichen Werthaltigkeit von Influencermarketing überhaupt anstellen?
Gerade der erste Punkt ist – zumindest aus meiner Sichtweise heraus – eines der wichtigsten Aspekte, die man schlichtweg in der Zusammenarbeit mit diesen Influencern zu beachten hat. Hierzu fand ich in den letzten Monaten und Jahren mehrfach Gelegenheit zur Durchspielung von „Pushansätzen“, die ich in diesem Beitrag einmal kurz beschreiben möchte. Vorab: sämtliche Punkte entstanden aus einem gigantischen Schwall an Inspirationen, den ich bekam, als ich einmal dieses „Influencermarketing“ inkl. entsprechender Accounts durchanalysierte und die Ansätze wurden mehrfach bei Testszenarien und klassischen Experimenten durchgespielt, wobei jeder einzelne Account stabil ist, nachwievor existiert und sich erstaunlich hoher Beliebtheitswerte erfreut.
[Erklärung]
Die nachfolgenden Punkte zeigen verwendete Ansätze und Werkzeuge und laden keinesfalls dazu ein, das ganze im eigenem Umfeld selbst durchzuspielen. Sprich: hier übernimmt keiner Verantwortung dafür, wenn die Leser_innen sich mit den vorgestellten Sachen die eigenen Accounts „verbrennen“ und / oder nicht die gewünschten Wachstumsraten erwirtschaften.
(1) Organisation von Likes – Organisch.
Mir fallen unfassbar viele panikmachende Blogbeiträge und Diskussionsbeiträge und Forenbeiträge ein, wo mit starken Worten vor dem Tool „Gramblr“ gewarnt wird und ich forschte hier 2016 einmal nach und hinterfragte die Erkenntnisse, denn: zu Negativmeinungen gehören eben auch Belege, oder quasi Beweise, welche eben auch die Gefährlichkeit von „Gramblr“ nachvollziehbar machen können. Teilweise fand ich da ausweichende Argumente + viel Emotion und teilweise wurde mir gestanden, dass man eben Gramblr noch nie gesehen und verwendet hat. DAS animierte mich, mir das Gramblr einmal anzuschauen und dieses Werkzeug befindet sich jetzt im täglichem Einsatz. Also: ich lade damit Fotos hoch und selbstverständlich werden dort bei bestimmten Szenarien die Coins in Likes verwandelt. Hier noch einmal: weder das Hochladen von Fotos, noch die gelegendlichen „Pushs“ in Form von Coins->Likes haben in den letzten Jahren bis heute irgendein negatives Erlebnis hier produziert.
Nutzt man Gramblr, sollte man sich sehr genau anschauen, welche Likes denn von welchen Accounts da eintrudeln (naja … sofern man die entsprechende Funktion nutzt) und hier fallen mir sehr viele dieser „Microinfluencer“ auf. Hierunter fällt auch ein – mehr oder weniger – bekannter Komiker aus dem Sender Tele5. Ach … wie effektiv ist das Ganze: nunja, je nach investierten Coins und (Fake)likewellen, lassen sich in mittelschweren Nischenhashtags Rankings realisieren und man bekommt über die (halb)automatischen Likes natürlich auch Zugriff auf die Reichweiten DER Likenden.
Ich rede recht häufig über dieses Werkzeug im Kreise der Influencermarketingbetreibenden und stelle immer wieder fest, dass trotz nicht vorhandenem Hintergrundwissen zu dem System „Gramblr“ man zwar eine Meinung dazu hat (Warum eigentlich?) und sich nicht vorstellen kann, dass dieses Tool nicht von Influencern benutzt wird. Seltsam, oder?
Eine weitere Likeorganisation kann über die Engagement Gruppen laufen. Ich bevorzuge sogar diesen Weg, weil sich dort – nach ersten Sichtungen – extrem professionell aufgestellte Influencer tummeln und hierüber ein Likemodus organisiert werden kann, welcher „sanft“ oder „natürlich“ ausschaut. (Vergleich: Gramblr produziert Likewellen)
Der Aufwand ist – im Vergleich zur Gramblrvariante – geradezu „niedlich“ (Siehe hierzu: Engagement Gruppen
Achja, dann existieren noch weitere automatische Likeorganisationsvarianten und diese drehen sich auch um den beliebten Bot „Ninjagram„. Die Lizenzkosten bewegen sich in einem niedlich geringem Rahmen und das Programm deckt alles ab, was das kleine Automatisiererherz sich so vorstellt. Auf die konkreten Funktionen und die Potentiale möchte ich an dieser Stelle nicht eingehen, da die Leser_innen mit hoher Wahrscheinlichkeit wissen werden, was ein automatische abgegebener Like bewirken KANN.
Weiterhin existiert in den Bereichen der Likeautomatisierungen auch ein spannender Service, der den faszinierenden Namen „addmefast“ trägt. Diese funktioniert auch auf Basis eines Coinsystem … man bekommt also eine virtuelle Währung gegen Aktivitäten gutgeschrieben und kann das „Geld“ in Likes, neue Fans, Daumen hoch u.v.m. reinvestieren. Erste Experimente zeigten mir da eine interessant hohe Dichte an Influencern.
(2) Organisation von Likes – Kauf.
Weil ich vom direkten Kauf dieser Likes nichts halte, beschränke ich meine Ausführung auf die Verlinkung zu entsprechenden Google-Anfragen:
https://www.google.com/search?q=buy+instagram+likes+cheap
https://www.google.com/search?q=buy+1000+instagram+likes+for+%241
https://www.google.com/search?q=likes+kaufen+instagram+paypal
usw. usw. usf. (Nur mal am Rande bemerkt: der Markt ist absolut gigantisch).
Zurück zur Socialmedia/Influencermarketingakquiseveranstaltung, welche als „Vortrag“ deklariert wurde:
Als Verifikation zu Fake / Non-Fake wurden mir zwei Optionen angeboten (Achtung: die oben dargestellten Pushorganisationsmöglichkeiten kannte man nicht und man möchte sich auch nicht damit beschäftigen): (a) Erfahrung und (b) alte Datensätze von Tools, welche vor den letzten Instagram-Änderungen noch funktionierten, wobei die Datensätze ausschliesslich Follow / Followerveränderungen zeigten.
Ich sehe nun folgende Probleme:
Erfahrungen und Erfahrungswerte sind rein subjektive Zustände, die keiner kritischen Gegenprüfung (erst recht nicht, wenn man die Automatismen nicht kennt …) standhalten dürfte und alte Datensätze sind schlichtweg unbrauchbar, weil diese eben _alt_ und wegen API-Änderungen schlichtweg für die Klient_innen des Influencermarketings nicht nachprüfbar sind. Ich frage mich auch, welche besondere Werthaltigkeit nun eine Strategie hat, die keinerlei saubere Monitoring der Kooperationsaccounts hat und in einer Welt aktiv ist, deren Schwerpunkte auch in der (halb)automatisierten Reichweitenproduktion liegen. Weiter noch: man darf niemals davon ausgehen, dass sämtliche einkaufbare Reichweiten auch wirklich sauber / moralisch organisiert sind und ich rate auch an dieser Stelle dazu, keinerlei Moralisierungen zu den o.g. Strategieauszug zu tätigen oder auch Dienstleister_innen mit Hang zur Moralisierung einzukaufen.
Komme ich nun zu meiner privaten Prüfliste bzgl. der Zusammenarbeit oder Gesprächen mit Influencermarketingdienstleister_innen / Influencermarketingagenturen in Form eines Fragenkataloges.
(1) Wie werden die Trafficprognosen via Influencermarketing berechnet und welche Datenquellen werden da benutzt?
(2) Wie werden die Kooperationspartnerschaften kontrolliert und welche Datenquellen werden für die Verifikationen der Reichweiten und Interaktionen benutzt?
(3) Welche konkreten Accounts hast Du selbst positioniert, wie sehen die Effekte aus und welche Erfahrungen hast Du mit den verschiedenen Strategien (organisch, nicht-organisch)?
(4) Welche Tools verwendest Du?
(5) Kennst Du die APIs der Socialmedia und wie nutzt Du Diese?
(6) Welche Accounts hast Du denn auch mit „bösen“ Strategien positioniert, oder beziehst Du Deine Warnungen nur auf Fremdberichte?
Wesentliche Punkte sind und bleiben die Datenquellen und die haben so organisiert zu sein, dass Diese für interessierte Laien einfach zu verstehende Ergebnisse produzieren. Weiter noch: ich verlange >1 Datenquelle, mit mind. einer Ressource aus dem Umfeld API. Der zweitwichtigste Punkt in meiner Privatliste ist die Sauberkeit der Prognosen zu Traffic und Umsatz und hier lese und höre ich immer wieder das Schema der nachgelagerten Landingpage. Also: man baut Landingpages zu Produkten auf und nimmt hierfür viel Geld und „hofft“ quasi auf Traffic und möglichst viel Umsatz. Unterhalte ich mich nun mit einem Branchenvertreter aus „Influencermarketing“, welcher u.a. mit „Erfahrung“ argumentiert, erwarte ich die Präsentation von bestehenden Accounts, welche u.a. mit Hilfe von Bit.ly-Urls arbeiten. Diese URL-Form erlaubt zwar nicht die externe Sichtung von Umsätzen, sie zeigt jedoch durchaus eine relativ saubere Auswertung von Trafficvolumina und hier gilt ja auch die Logik „mehr Traffic“ -> „mehr Umsatz“. Interessant ist die Rechercheform via Bit.ly-Urls-Prüfung auch, weil über die API eben auch die Zugriffe Herkunftsländern zugeordnet werden kann.
Der Punkt 06 fällt mir in den vielen Diskussionen immer wieder auf: man schreibt viele Dinge herunter, moralisiert stark und muss auf kritischen Nachfragen quasi zugeben, über keinerlei Erfahrungen zu den bspw. o.g. „bösen Strategien“ zu besitzen. Hier wundere ich mich immer wieder darüber, dass in einer logik- und zahlengetriebenen Szene / Branche eben völlig unlogisch argumentiert wird und ich frage da auch nach, interessiere mich für das Ausbleiben von Experimenten und Gegenchecks. Da wird mir immer wieder auch Folgendes kommuniziert:
(1) Agenturen haben keine Zeit für sowas.
(2) Wir haben keine Leute für sowas.
(3) Wir verstehen sowas nicht.
(4) Wir sind sauber / moralisch gut und fassen sowas gar nicht an.
(5) Wobus, bitte geh weg mit Deinem Nerd-Zeug.
Mich gehen selbstverständlich diese oder jene geschäftlichen Interna nichts an und der Markt regelt sich da schon eigenständig. Ich würde mich allerdings fragen – sofern ich den Einkauf entsprechender Dienstleistungen plane -, welchen Wert die angesprochenen Dienstleister_innen denn im Interesse MEINER Planungen, Prognosen und Wünsche haben, wenn sämtliche Argumente auf nicht greifbare Erfahrungen, offensichtliches Nicht-Wissen zu „alternativen Strategien“ und subjektiv geprägter Moralvorstellungen basieren. Mhhhh …
Fragen? Gedanken? Austausch gewünscht? Konkrete Projektanfrage? Ich freue mich über Rückmeldungen.
Linkaufbau: Wenig (Domain)quellen vs. Backlinkanzahl aus (Domain)quellen
In einem Branchenforum entdeckte ich heute eine interessante Frage, welche auf folgendes Problem hindeutete:
Man hat Linkaufbau auf Basis der typischen Blogcomments betrieben und wundert sich nun über den Effekt, dass die WMT sehr schnell unfassbar viele Links anzeigen. Natürlich rufen diese Zahlen entsprechende Panikreaktionen hervor und das beobachtete Phänomen bezieht sich eigentlich auf eine sehr simple Blogdarstellungstechnologie. Diese kann ich bei folgenden Zuständen beobachten: (a) an statischer Stelle (Sidebar …) befindet sich das „letzte Kommentare“ – Widget und (b) an statischer Stelle (Sidebar …) befindet sich eine Blogroll.
Welche „Konsequenzen“ hat das nun im Bezug auf die Linkauflistungen in den WMT?
Option „letzte Kommentare“
In der Regel befinden sich in den meisten dieser Widgets die letzten 3-5 Kommentare und diese Liste bleibt solange „statisch“, bis weitere Kommentare im jeweiligen Blog „produziert“ werden.
Option „Blogroll“
Hier beobachte ich völlig verschiedene Darstellungstypen. Ich bevorzuge bei unseren Systemen i.d.R. eine Mischform zwischen „statischer“ Blogroll und „dynamischer“ Blogroll. Die zweite Variante läuft u.a. darauf hinaus, dass ich in bspw. den Fotoblogs die spannenden Links in die entsprechende Tabelle eintrage und mit Hilfe eines Zufallsgenerators (WordPress liefert diesen „frei Haus“) ausspiele.
So … was passiert nun, wenn der Google-Bot den linkspendenden Blog „besucht“? Es ist eigentlich recht simpel: der Bot schaut sich mal mehr und mal weniger „intensiv“ die dargebotenen Medien (Texte, Bilder, whatever) an und stellt fest, dass bei den besuchten Medien „nahebei“ (hier: Sidebar) gesetzte Links liegen (Comments, Blogroll usw.) und spielt das genau in der Form auch in die jeweiligen Datenbanken / WMT-Accounts aus.
Nun taucht immer mal wieder panikartiges Nachfragen hier und da auf und Kern solcher Statements ist immer dieses subjektiv wahrgenommene Schwert über den Köpfen der Linksetzenden. Ich sehe das Thema / die Beobachtung außerordentlich entspannt und begründe das mit den Stand des Arbeitsblog, denn: letztes Jahr setzte ich einen Link (Natur: „harter Linktext“ -> „professionelles Internetmarketing“) auf eines unserer „Pseudohobbyprojekte“ (Fotoblog).
[Bild: WMT-Auszug, anonymisiert]
[Bilder: Xovi-Auszüge]
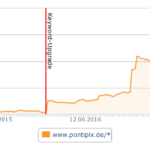
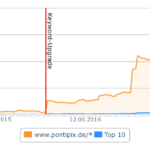
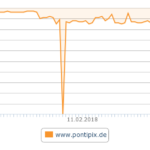
Die Beobachtungen resultieren aus einem alten Experiment und belegt zumindest mir, folgende Thesen:
-> gigantisch erscheinende Linkmassen, zu finden in den WMT, sind nicht „schlimm“
-> Linkaufbau via Blogcomments und Blogrolls sind nicht „schlimm“ / „böse“, wenn:
(a) die Linkspender etwas anbieten, was Zielgruppen suchen
(b) Zielgruppen eindeutig „sagen“, dass der Linkspender „gut“ / „wertvoll“ ist (auslesbar via Socialsignals, Bitly-Variante)
(c) der Linkspender für eine Contentqualität sorgt, welche von den Zielgruppen als „gut“ / „wertvoll“ interpretiert und auch „abgenickt“ wird (auch auslesbar via Socialsignals)
(d) der Linkspender für einen guten Fluss an neuen Content sucht, wobei der Content nicht nur von den Zielgruppen „abgenickt“ werden muss, sondern auch quasi Trends beschreibt, neue Wege geht, innovativ ist und neue Wege geht.
(e) der Linkspender einen guten (Achtung: subjektiv bewertet …) Umgang mit den Socialmedia pflegt.
Woocommerce (Affiliatekatalog) – „Werkszustand“ (Update 18.05.2018)
Die nachfolgenden SQL-Statements helfen beim Löschen aller Produkte aus einem Woocommerce-Affiliatekatalog.
Voraussetzung:
Im ersten Schritt müssen alle Produktfotos aus dem jeweiligen Uploadordner entfernt werden (via Putty, via FTP). Bei großen Projekten empfehle ich die Putty-Variante mit Hilfe des Befehls „rm -r [uploadordner]“. Alternative Löschmöglichkeiten sind natürlich die FTP-Clients oder die Anwendungen auf dem Webspace / Server.
SQL-Queries:
1. Bereinigung der Tabelle [prefix]_posts
delete from wp_posts where post_type ='product'; -> Produkte löschen
delete from wp_posts where post_type ='attachment'; -> Produktbilderverweise löschen
2. Bereinigung der Tabellen vom wpallimport
truncate wp_pmxi_posts;
3. Bereinigung der Tabelle [prefix]_postmeta
DELETE `m`.* FROM `wp_postmeta` as `m` LEFT JOIN `wp_posts` as `p` ON `m`.`post_id`=`p`.`ID` WHERE `p`.`ID` IS NULL -> ~80Sek Bearbeitungsdauer
4. Bereinigung der Tabelle [prefix]_term_relationships
delete termrel from [prefix]_term_relationships as termrel left join [prefix]_posts as post on (post.id = termrel.object_id) where post.id is null
5. Ergänzungen / Sonstiges
TRUNCATE wp_404_to_301;
truncate wp_yoast_seo_meta;
TRUNCATE wp_external_links_masks;
Woher kommt der Traffic? (Socialmedia-Analyse(n))
Vor ein paar Tagen nahm ich mir etwas Weiterbildungszeit und sichtete diverse WWW-Marketing-Wochenabschlussbeiträge. Zur Info: diese besondere Art der Blogbeiträge beschreibt meistens eine Wochenzusammenfassung an besonders faszinierenden Links und externen Beiträgen. Aus logischen Gründen stand aktuell meistens Facebook und / oder die generelle Arbeit mit den Socialmedia im Fokus und ich wurde aufmerksam / munter, als ich das Dokument „Pinterest, Google, & Instagram big winners as Facebook share of visits falls 8% in 2017“ von Shareaholic da gesehen hatte und hier ist eine Klischeesituation aufgefallen:
[1] Eine Autorität veröffentlicht Beobachtungen
[2] Eine Subautorität nimmt die Beobachtungen daher, ergänzt diese um einige Anmerkungen
[3] Unfassbar viele Dienstleister_innen nehmen die Inhalte aus [2], um diverse Existenzberechtigungen herbei zu argumentieren und sog. „hochwertigen Content“ zu produzieren.
Der gemeinsame Nenner zwischen [2] und [3] ist hier – ganz im Sinne der Klischees – das bewusste Nicht-Hinterfragen der Thesen aus [1], da man es ja mit einer wahnsinnig anerkannten Autorität zu tun hat. Ich erkenne jedenfalls keinerlei Logik in dieser faszinierenden Gangart und Branchenautoritäten müssen sich jedezeit hinterfragen und fachlich kritisieren lassen. Aus meiner Perspektive generiert sich genau aus diesem Merkmal die Berechtigung des Labels „Autorität“ und es ist mir schleierhaft, warum gefühlt sämtliche Autoritäten der Marketingbranchen den fachlichen Konflikt meiden.
Wie auch immer und zurück zum Shareaholic-Artikel kommend.
Ich unterstelle Shareaholic aus sehr guten Gründen eine gewisse Grundkompetenz bzgl. der Aus- und Bewertung von Socialsignals, nur befinden sich im Beitrag diverse Lücken:
[1] Keine Offenlegung der analysierten Seiten.
[2] Keine Offenlegung der Länder und Zielgruppen zu den analysierten Seiten.
[3] Keinerlei Offenlegung der zeitlichen Entwicklung der Signals / Socialbewegungen über den kompletten Zeitraum von 2017.
[4] Keinerlei Offenlegung der Datenerhebungsmethoden.
Gerade der 4. Punkt wirkt auf mich – vorsichtig formuliert (!) – mehr als verwirrend und ich frage mich, warum den DACH-Kolleg_innen nicht aufgefallen ist, dass Instagram schlichtweg keinerlei Möglichkeiten zur Analyse von Traffic von externen (also: nicht selbst betreuten!!!) Seiten und Projekten liefert: es existiert keine einzige Möglichkeit, mit Schnittstellen / API-Endpoints den Traffic von völlig unbetreuten Accounts zu deren Webseiten zu erfassen. Da frage ich mich: Wie hat das Shareaholic geschafft und wo genau befindet sich da die Dokumentation? Diese sehe ich nicht und Querchecks via Google und diverse „Nerd“-foren ergab keinesfalls eine Problemlösung.
Es bleibt also folgende Frage offen: Warum bewirbt man mit völlig intransparenten Datenerhebungen ein Socialmedium zum Zwecke der Trafficgenerierungsansätze? Ich sehe hier keinerlei Logik oder sogar Gesprächsgrundlage für diese oder jene Projekte.
Genau diese Problematik beschäftigte mich die letzten 2 Tage und das Ergebnis entsprechender Gedankengänge ist:
[1] Instagram
Der Traffic via Instagram lässt sich definitiv nicht sauber monitoren, wenn keinerlei Zugriff auf eine hinreichend große Accountmasse (Hier: alle Themen, Länder, Branchen etc.) besteht. Man kann also nur mit Hilfe der Indikatoren hier Analysen anstellen und ich wage die Formulierung folgender Thesen:
(a) Der Traffic ist hoch, wenn möglichst viele Interaktionen auf den Postings der jeweiligen Accounts identifizierbar sind, wobei hier zwischen Botgesteuert und „Organisch“ zu unterscheiden ist.
Quellen:
Beiträge aus „Interaktionenprojekt“
InstagramAPI (Endpoint -> Likes)
InstagramAPI (Endpoint -> Comment -> Get)
(b) Der Traffic kann hoch werden / sich gut entwickeln / ist hoch, wenn die Postings der jeweiligen Accounts entsprechend „mächtige“ Hashtags verwerten.
Quellen:
Beiträge aus „Hashtagprojekt“
Datenbanken zu „Hashtagprojekt“
InstagramAPI (Endpoint -> GetTag)
Werden über die bekannten und dokumentierten API-Endpoints bspw. zu Instagram die notwendigen Daten erhoben, stellt man sehr schnell etwas „Lustiges“ fest:
Die Datenmassen können zwar extrem umfangreich sein, jedoch bilden Diese immer einen recht kleinen Moment aus dem Universum von Instagram ab. Sie lassen sich maximal im Rahmen der Datenbankinhalte verwerten und können keinesfalls Aufschluss über unbekannte Themen und Untersuchungsobjekte liefern. Dann weiter: die Verwertung dieser technischen Schnittstellen zeigt ab einem gewissen Punkt die Begrenztheit, weil eben diese Endpoints nur eine begrenzte Menge an Abfragen zulassen. Instagram ist hier recht liberal oder „großzügig“, andere Socialmedia jedoch nicht (siehe: Twitter und die Retweet / Tweetzählproblematik).
Fazit zu Instgram:
Absolute Aussagen zu „Traffic“ im Vergleich zu den anderen Socialmedia lassen sich nicht sauber generieren, man arbeitet da mit „Vermutungen“ und die Sauberkeit eben dieser Vermutungen / Prognosen hängt ab von:
– Offenlegung der Erhebungsverfahren
– Gegenprobe via API-Endpoints
– Menge der erhobenen Daten aus „API-Endpoints“ inkl. deren inhaltlichen Breite
Diese Sachen sehe ich weder im o.g. Report, noch in den Szenecontentmarketingaktivitäten.
[Andere Socialmedia außerhalb von Instagram]
Am 6.12.2013 fand ich Gelegenheit, ein Projekt fertig zu stellen. Dieses ist auch Bestandteil unserer Monitoringaktivitäten und begutachtet die Socialsignalentwicklungen aus Facebook, Twitter und Pinterest. Früher empfand ich noch die Notwendigkeit, Google-Plus zu beobachten und die entsprechende Funktion wurde im Laufe der Jahre eingestellt, da besagtes Medium eine extrem untergeordnete Rolle spielt. Die Kernidee hinter dem Projekt entstand eigentlich bereits in den Jahren 2010-2011, als wir – aus einem Zufall heraus – die Socialmedia (damals primär Twitter und Friendfeed) als spannendes Promomittel entdeckten und hierüber geradezu euphorisierende Rankingeffekte (einhergehend mit Traffic und Umsatz) produzieren konnten. Es war damals für alle Beteiligten absolut sichtbar und klar, dass selbstverständlich Traffic über die verwerteten Socials organisierbar IST und aus dieser Beobachtung leitete ich damals (!) folgende These ab:
Der Traffic via Twitter, Facebook u. anderen ist von der Sichtbarkeit abhängig und die Sichtbarkeit der der Postings ist abhängig von den Interaktionen auf dem Posting.
Die Thesenverifikation lässt sich via Quercheck auf die Interaktionszähltools und entsprechende APIs realisieren, wobei man hier selbstverständlich in regelmäßigen Abständen Prüfungen durchzuziehen hat.
Twitter: https://opensharecount.com/
Pinterest: https://api.pinterest.com/v1/urls/count.json?callback%20&url=deineurl.org
Facebook: https://www.kickstartcommerce.com/use-facebook-graph-api-get-count-url-likes-shares-comments.html
Obwohl ich dazu neige, bspw. aus den Socialsignalszahlen generelle Trafficprognosen abzuleiten, neigt die liebe Anne Lehmann hier zu einer gewissen „Erbsenzählerei“ und sie zwang mich irgendwann dazu, eine weitere Gegenprobe funktion zu suchen. Diese fand ich in dem Ansatz über die Bit.ly-API und unser Monitoringwerkzeug erfasst diese Zahlen parallel zu den Daten aus den genannten Interaktions/Signalszähler. Hierbei muss natürlich beachtet werden, dass ein (relativ) sauberes Trafficmonitoring nur dann funktioniert oder „aufgeht“, wenn die begutachteten Projekte eben auch mit Bit.ly-URLs arbeiten.
Fazit aus meiner „Arie“.
-> Manche oder viele Autoritäten verdienen zwar einen gewissen Vorschuss an Vertrauen, jedoch muss die Autorität hinterfragbar sein und diese Vorraussetzung ist nicht gegeben, wenn Datenerhebungswege oder Grundlagen dieser oder jener Thesen nicht offen gelegt werden.
-> Der kritiklose Umgang mit „Studien“ und / oder Autoritäten birgt die Gefahr von falschen und gefährlichen Strategien im Onlinemarketing.
Fragen? Anmerkungen?
Instagram – Livevideos (für weitere Verarbeitung und Vermarktung) downloaden
Im Zuge der Etablierung diverser „Pseudohobby“-Projekte mit Schwerpunkt auf „Fotos“ und „Analogfotos“ suchte ich nach einer Lösung, welche einmal abgedrehte Livevideos für die Verteilung in bspw. Youtube-Konstellationen überhaupt erlaubt. Instagram liefert mit den Boardmitteln / via App die Downloadoption – als Feature – direkt nach der Videobeendigung, allerdings ohne Kommentare der jeweiligen Zuschauer_innen.
Eine interessante Kompensationslösung liefert das Chrome-Plugin „Chrome IG Story„. Die Bedienungsanleitung ist laiengerecht gestaltet und formuliert. Das Download hat das Format „mp4“ und die Qualität der Datei entspricht den üblichen Standards.
