Vor einigen Wochen fand ich etwas Zeit, um mich mit alternativen Accountaufstellungsmethoden auseinander zu setzen und im Rahmen der – obligatorischen (!) – Recherchearbeiten entdeckte ich das magische Reizphrase „Engagement Gruppen“. Hier erinnerte ich mich an äußerst hitzige Diskussionen, geführt von mir, in irgendeiner dieser Facebook-Instagram-Gruppen und ich muss gestehen, dass ich das Thema „Gruppen nutzen JA vs. NEIN“ sehr lange auch sehr emotional gesehen habe. Warum sich das änderte, kann ich nicht genau spezifizieren.
Also … im Laufe meiner Suche nach Inspiration entdeckte ich natürlich diverse Hürden, da die wenigen (!) professionellen deutschen Berichte zu diesen Gruppen den Zugang zu dieser Strategie als wahnsinnig kompliziert darstellten und parallel dazu die ersten Berichte auftauchten, welche diverse Gegenmaßnahmen seitens Facebook und Instagram (Instagram ist ja eine FB-Tochter …) sehr logisch darstellten. Ich begriff schnell, dass diese Gruppen zwar existieren, gepflegt und genutzt werden, aber dass man sich natürlich von Organisationen innerhalb des Facebookuniversums fernhalten sollte (also: alles meiden, wo diese Geschichten in Facebook, Whatsapp UND Instagram laufen).
Ich entdeckte durch den obligatorischen Quercheck auf die Blackhatszenenforen einen weiteren „magischen“ Hinweis auf „Telegram“ und fand folgendes Dokument „Instagram Engagement Pods – FREE List of 124 Groups„. Ausgestattet mit wenig unerklärbaren Ängsten und einem gewaltigen Schub an Experimentierfreude organisierte ich mir auf Basis der Liste einen Telegramaccount und fing an, meinen Spieltrieb da auszuleben.
Hier sind meine Beobachtungen:
Es gibt gewaltige Gruppenunterschiede: zum einen befinden sich in dieser Sammlung botgesteuerte Gruppen, die sehr genau das gegenseitige „Beliken“ erfassen und schnell inaktive Accounts „bannen“, zum anderen existieren da Gruppen mit starkem Autolikebotbezug und wiederum fand ich da Gruppen, die völlig ohne Kontrolle und Disziplinarmaßnahmen funktionieren. Die eigentlich faszinierende Beobachtung, die ich da tätigte ist Folgende: selbstverständlich reihte ich meine Testaccounts da ein und ich entdeckte einen gewaltigen Zulauf an Interagierenden, welche aus Deutschland kommen, einkaufbare Influencer sind, extrem gute Bildsprachen zeigen, sehr professionelle Bildbeschreibungen und Tagwolken produzieren und mir gelang es, dass ein sehr bekannter Account aus „Radio“ (Kunst und Kultur) meine Medien beherzte und teilweise auch kommentierte.
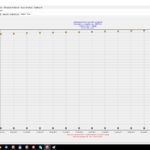
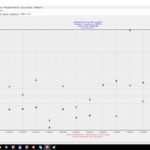
Im Ergebnis wurde die Reichweite(n) von 5 Accounts massiv gesteigert, ich konnte über das Medium „Engagement Pods“ sehen, dass eine sehr große Menge an Influenceraccounts genau dort einen Teil der Positionierungsarbeiten betreiben. Einer der Testaccounts erlebte eine Reichweitensteigerung von Startwoche i.H.v. ~1800 zu letzte Woche i.H.v. ~40.000 mit entsprechend hohen Interaktionen und der Pflegeaufwand ist hier erstaunlich gering. Entgegen der panikmachenden „Fachartikel“ (naja … eher Meinungen, Thesen etc.) beschränkte sich die Arbeit am Experiment auf ca. 8h Lernen, Testen, Gruppen anschauen und genau 7 Aktivitäten (hier: Liken der dargebotenen Medien und Eintragen der Medien, welche ich gern beliken lassen möchte). Das Experiment lief genau 3 Wochen bis letzten Sonntag.
Mein Fazit ist:
man kann und sollte diese Strategieform genauer prüfen und mit den internen Richtlinien / Gedanken zu „Moral“ und „macht man nicht“ abgleichen, denn man muss sich definitiv bewusst sein, dass hier ein Werkzeug vorliegt, welches große Influenceraccount in einen Art Likezwang versetzt UND hierüber die Fanbase / Reichweite besagter Accounts benutzt. Diese schnelle Art der Verknüpfung ist auf anderem Weg nicht möglich und auch nicht über den Content-is-King-Weg lösbar. Ich meine aber auch erkannt zu haben, dass trotz „Gruppenzwang“ eine ordentliche Qualität geliefert werden muss, denn die teilnehmenden Accounts agieren da nicht immer streng maschinell / botgesteuert und entscheiden durchaus bewusst pro oder contra „Herzchen“. Interessant waren für mich auch wunderbare und inspirierende Diskussionen via DM über meine Bilder (AUSGEHEND VON DEN GRUPPEN! ;-) ), Kritik an meinen Bildern und das Ausformulieren von ganz konkreten Kooperationswünschen auf Basis meiner Bilder. Im Hintergrund dieser Erfahrungen und den einhergehenden Analysen frage ich mich nun einmal wieder, warum unfassbar viele der Marktteilnehmer_innen aus „Socialmediaberatungen“ mit Hilfe von hochemotionalen Texten, Aussagen und Thesen und Behauptungen (natürlich ohne jeglichen Beweis!) gegen diese Strategieform argumentieren und auf meine Rückfragen hin teilweise auch offen zugeben, noch nie im Leben diese Gruppen gesehen oder genutzt zu haben. Man kann davon halten, was immer man möchte. Ich sehe es so: in dem Moment, wo ich und die Wobus & Lehmann GbR Dienste aus den vielen Bereichen von bspw. „Instagramaccountpromotionen“ anbiete, muss ich mich zwangsweise auch im Interesse der Accounts, der Projekte und der vielen Ratsuchenden eben auch mit diesen Dingen beschäftigen, diese Dinge sauber bewerten und – je nach Szenarium – auch selbstverständlich einsetzen. Dann weiter: ich bewege mit mit der Wobus & Lehmann GbR in einem logiklastigen Umfeld und hier haben moralisierende Bewertungen von diesen oder jenen pushenden Strategien keinerlei Platz und eigentlich müssen sich die Branchenteilnehmer_innen folgende Fragen gefallen lassen und auch sich selbst stellen:
(a) Warum sollten die eigenen Klient_innen zwangsweise viel Geld in Instagram-ADs investieren? Weil das moralisch einwandfrei ist?
(b) Warum sollten die eigenen Klient_innen zwangsweise Kooperationen mit Influencern einkaufen, wenn völlig problemlos diese Gruppen identifizier- und beobachtbar sind und die pot. Influenceraccounts ganz sicher die vielfach kritisierten „Mittel“ selbst einsetzen?
Ich finde – für mich mich – es eleganter, die zu bewerbenden Accounts direkt in den Status „Influencer“ zu bringen (Strategiewahl je nach Typ, Branche, Medien etc.) und hierüber schwer kalkulierbare Posten (a) und (b) zu umschiffen.
Interesse an Gesprächen? Ich freue mich über Kommentare, eMails, Anrufe und konkrete Anfragen.