Mit Freigabe der aktuellen Dateninterpretationssoftware habe ich mich dazu entschieden, die Datenvisualisierungsfeatures auf „final“ zu stellen. Das bedeutet, dass die Diagramme, die konkrete Gestaltung etc. fertig gestellt sind und ich maximal einige kosmetische Dinge da einbauen werde. Diese sind:
-> Farbauswahlfeatures
-> Ausweitung der Taganalyse auf max. 10
-> div. sonstige Farbmanipulationen
[Screenshots zu den Diagrammen]
-

- Hashtagclient, absolute Werte
-
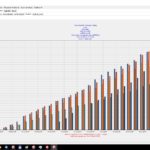
- Hashtagclient, absolute Werte „Balken“
-
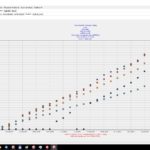
- Hashtagclient, absolute Werte – „Points“
-
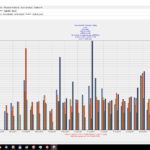
- Hashtagclient, absolute Werte je Datensatz -> Balken
-

- Hashtagclient, absolute Werte je Datensatz -> Points
Die Beispieldiagramme offenbaren hier einige Datenlücken und diese lassen sich so erklären:
-> Ausfall / Fehler der API-Endpoints
-> Änderungen an den API-Zugriffsmodalitäten und Abfragequota
-> Bug, Fehler im Scraper
[Screenshots zu den Rohdaten]
-
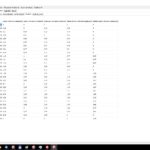
- Hashtagclient -> Rohdaten 01
-
- Hashtagclient -> Rohdaten 02
Nach intensiven Diskussionen rund um diese Datenlücken – intern und extern – fällte ich die Entscheidung, diese bewusst offen zu lassen und immer zur Gegensichtung der Rohdaten (siehe Screenshots zu raten. Sicherlich ist dieser Weg nicht „kosmetisch schön“, jedoch halte ich eine Datenauffüllung durch den Vorgängerwert für wenig zielführend, da hierüber eventuell Logiklücken in der Dateninterpretation sichtbar werden könnten.
