Im letzten Jahr fand ich endlich Gelegenheit zur Sichtung diverser Datenmanagement- und Datenauswertungsansätze, weil ich ab einem gewissen Punkt mit meiner Programmierkunst via Delphi viele Szenarien nicht abdecken kann.
So landete ich bei KNIME und fand einen guten Weg, die Workflows zu verstehen und in das Tagesgeschäft einbauen zu können. Interessant ist, dass dieses mächtige und sehr umfangreiche System gefühlt problemlos bspw. die 85GB umfassende Twitterdatenbank oder die 46GB starke InstagramDE/CH/AT-Datenbank andocken, bearbeiten und für diverse Dataminingszenarien ansprechen kann.
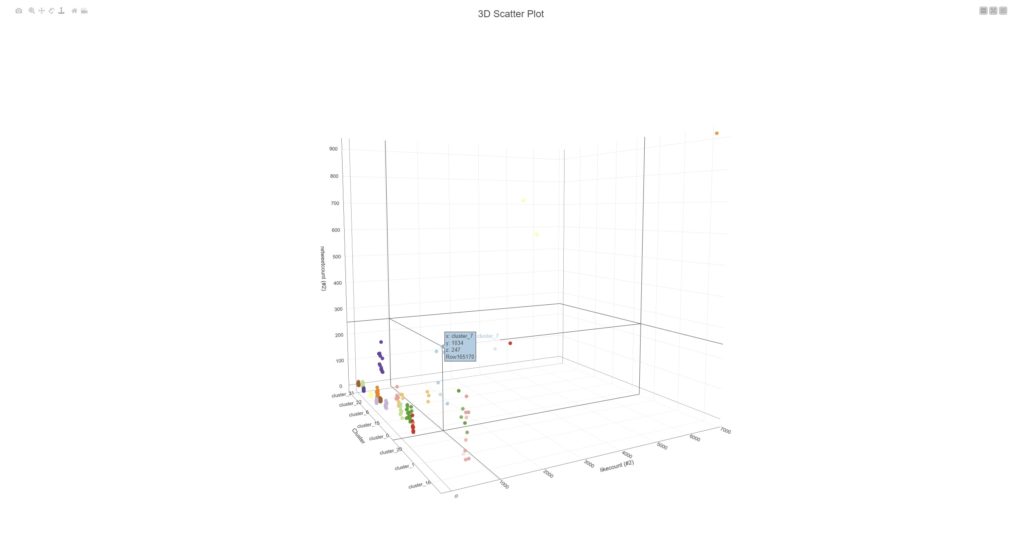
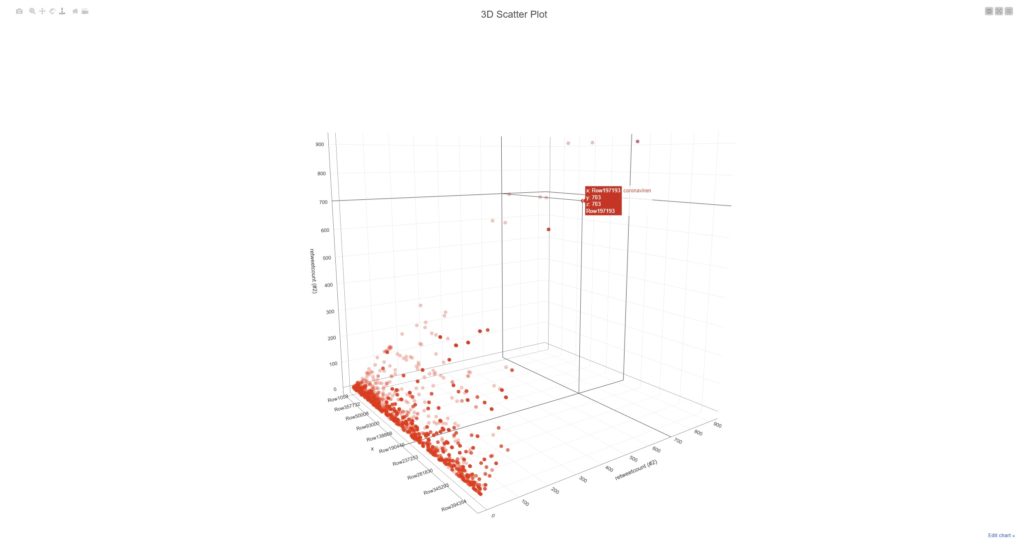
Galerie zeigt 2 Screenshots, welche Terms / Keywords aus den Meinungsbekundungen von ~3.8Mio DE-schreibenden Accounts (Twitter) mit Filter auf Covid19/Pandemie/Coronavirus (Themencluster).
Der „Trick“ ist eigentlich recht simpel: sofern die Datenerfassungsprozedur stabil funktioniert und die Datenbank ordentliche Standards (Technik, Struktur etc.) zeigt, wird via KNIME-Workflow eine Analysemechanik auf die Tweets quasi „angesetzt“. Diese zerlegt den Content in Einzelworte, gewichtet diesen mittels einer Prozedur, welche folgende Metriken beinhaltet:
- Interaktionen
- Zeitstempel
- Anzahl: aktiver Accounts mit Themenfilter
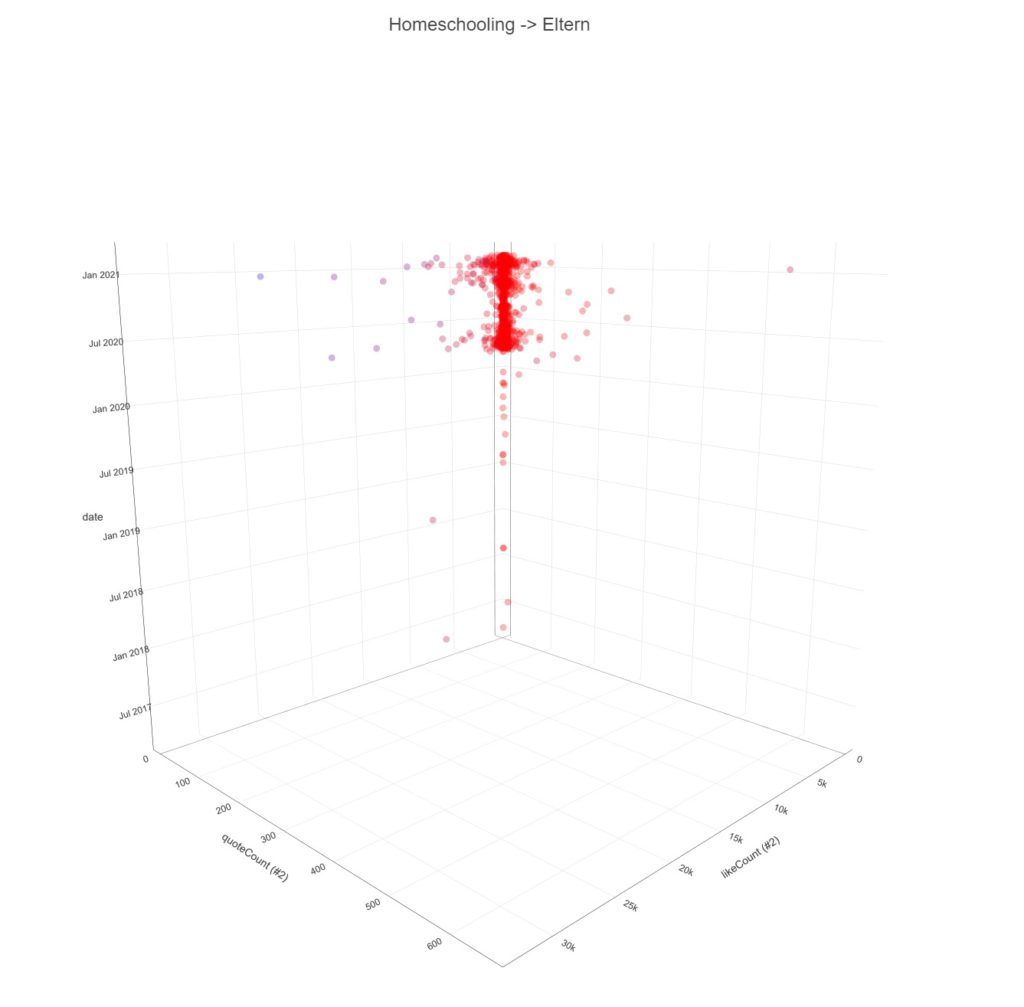
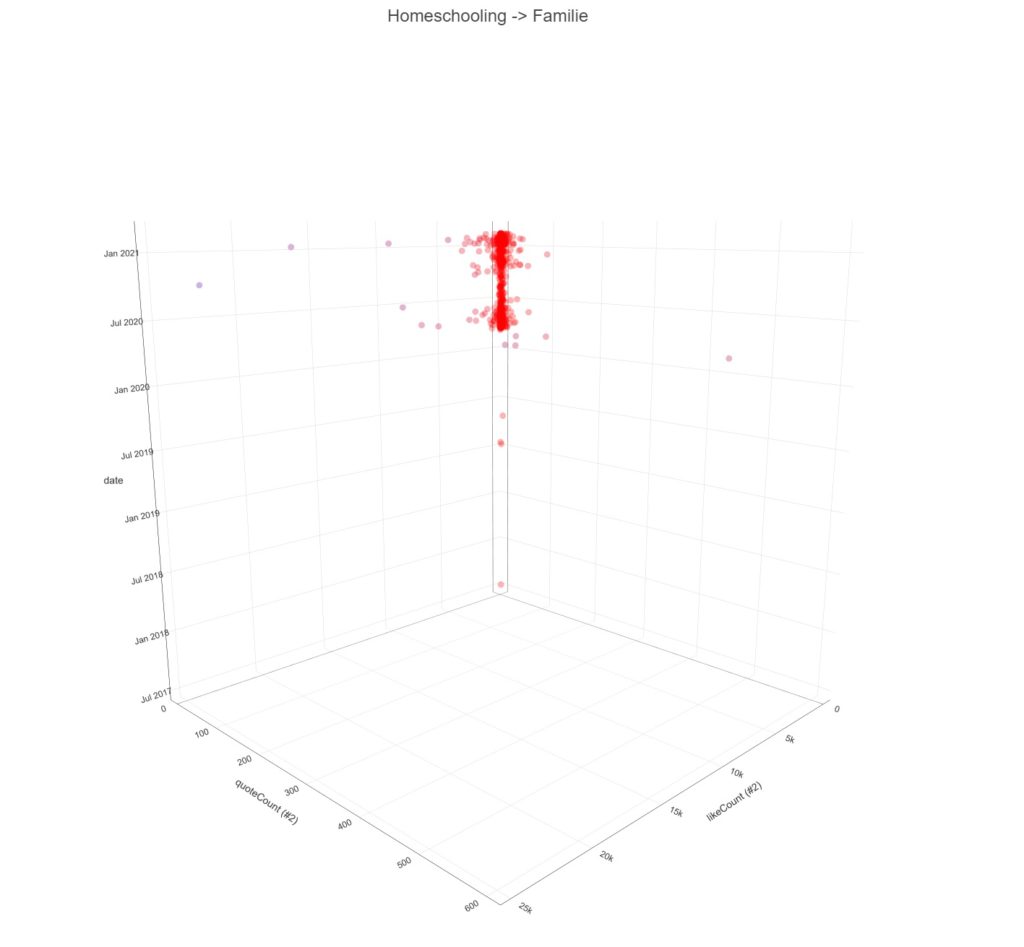
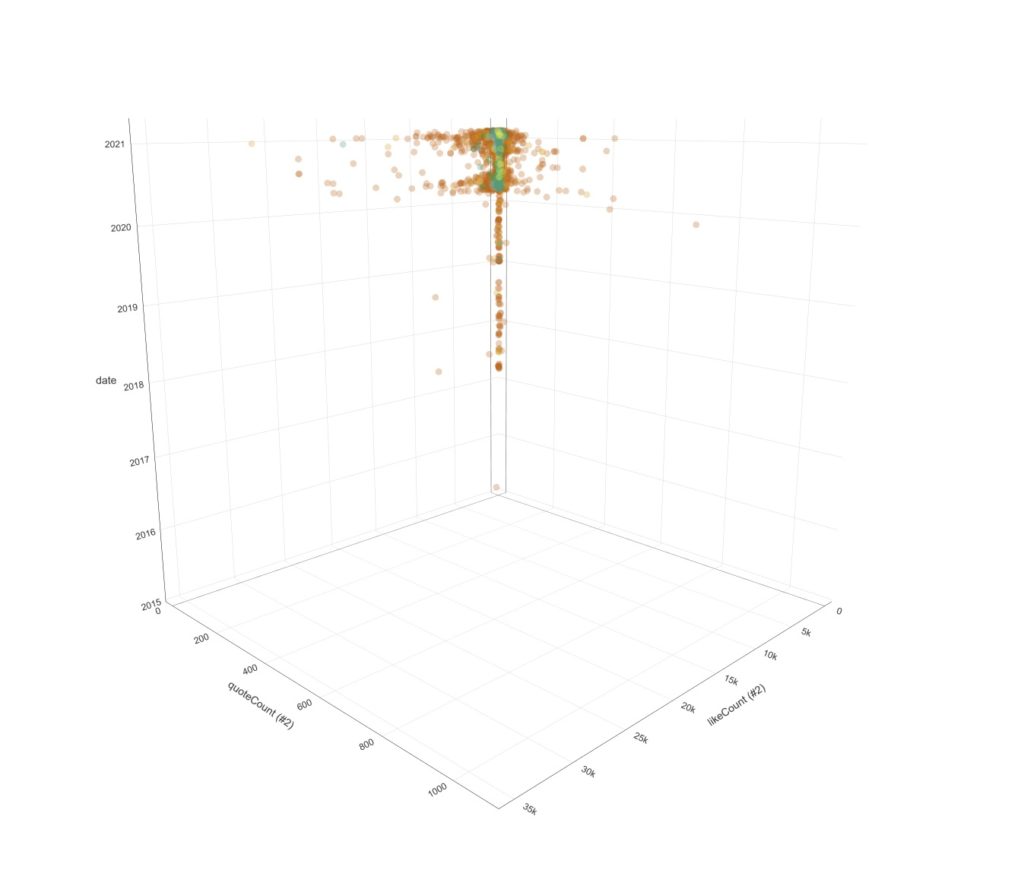
Über diesen Gewichtungsschritt sind Themenzusammenhänge der UnterCluster visualisierbar und das erste Bild der Galerie demonstriert die Zusammenfassung der Themenwolken in Filterblasenstrukturen.